Welcome to blog.mbedded.ninja!
Use the sidebar (wide screens)/menu (mobile) to navigate through the different sections of the site.
July 2026 Updates
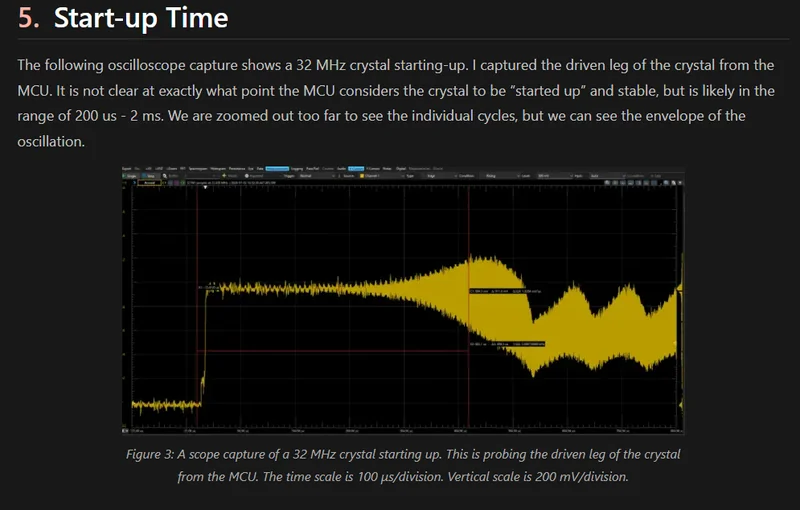
32 MHz Crystal Start-up
Added a oscilloscope capture of a 32 MHz crystal starting up.
ESLs
Added info on electronic shelf-edge labels (ESL) to the bistable displays page.
LED Matrix Displays
Added a page on LED matrix displays, covering how they work, multiplexed scanning, driver ICs such as the MAX7219 and HT16K33, addressable RGB matrices (e.g the WS2812B), and the HUB75 interface.

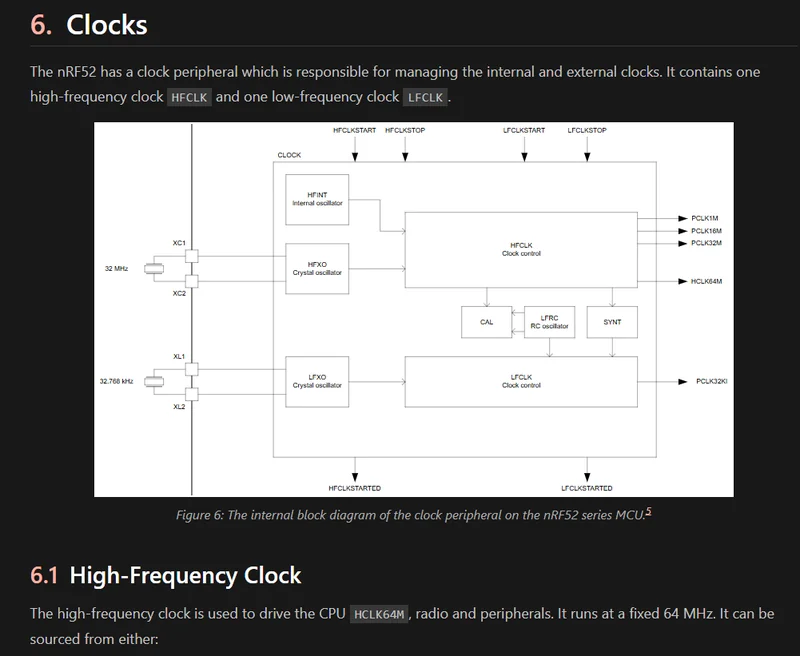
nRF52 Clock Peripheral
Added info on the nRF52 clock peripheral, including the various clock sources, tolerances and calibration.
nRF52 APPROTECT
Added info on the nRF52 APPROTECT security feature, including the improved APPROTECT in later silicon revisions, and how to disable it in firmware.

Depletion-mode MOSFET Current Source
Added a schematic of a depletion-mode MOSFET constant-current source to the discrete current sources page.
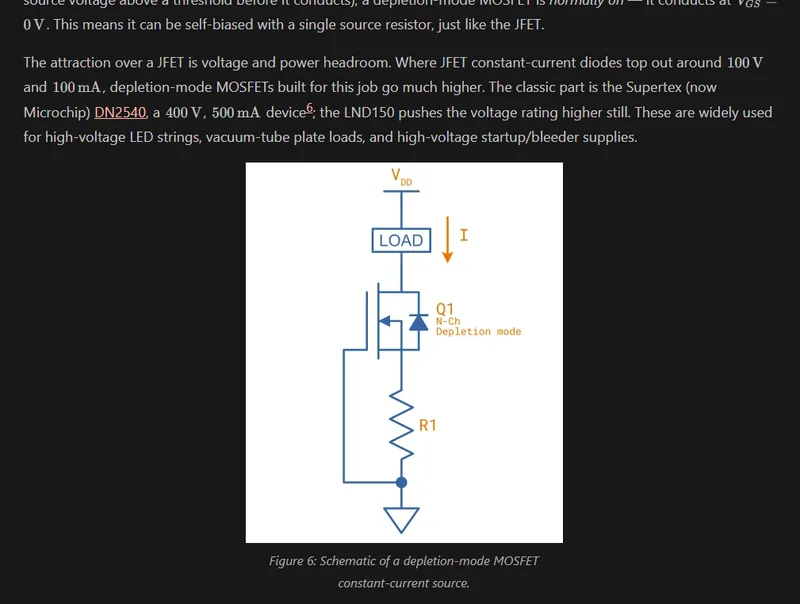
Current Source Resistor Calculator
Added a calculator for sizing the source resistor in a JFET or depletion-mode MOSFET constant-current source.
eMMC Memory
Added a page on eMMC memory, covering the interface, speed modes, partitions and how it compares to SD cards, raw NAND and UFS.

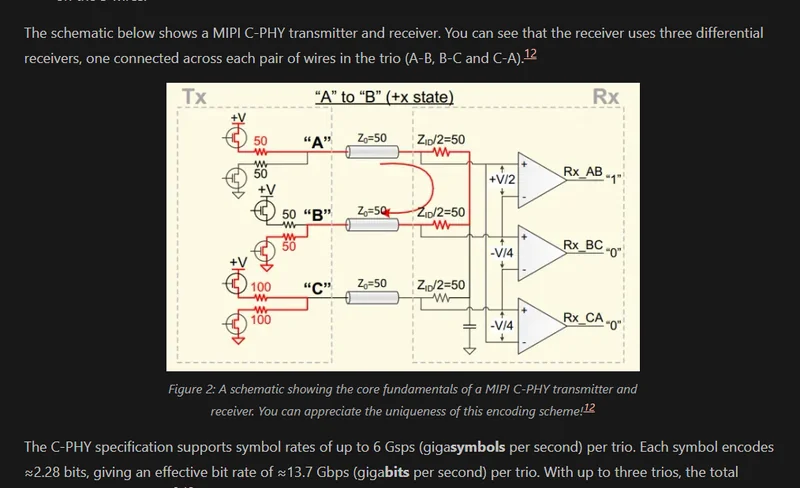
MIPI CSI Communication Protocol
Added info on the MIPI CSI communication protocol, including the different versions of the protocol, and the D-PHY and C-PHY physical layers for MIPI CSI-2.
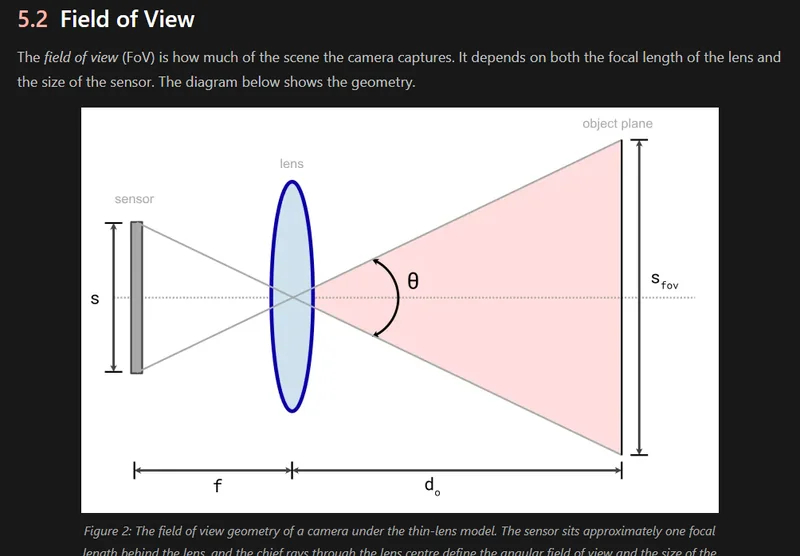
Cameras and Lenses
Added info on cameras and lenses, including camera sensors, camera modules, lens types, and field of view calculations.
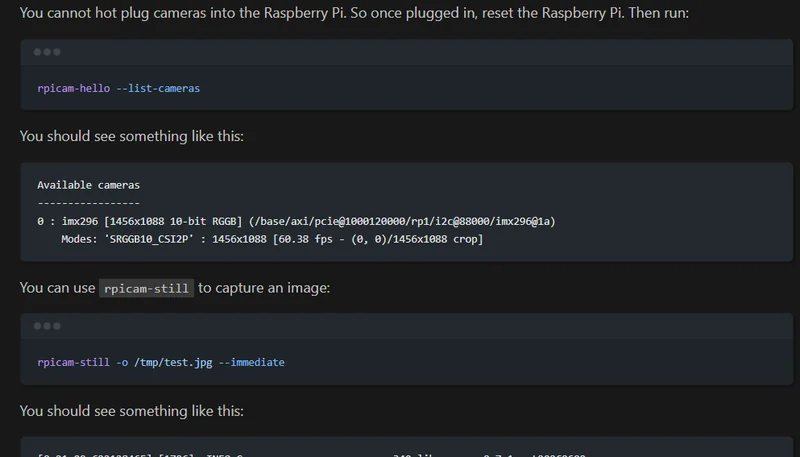
Raspberry Pi Cameras
Added a page on Raspberry Pi cameras, covering how to use the Raspberry Pi camera modules, the picamera2 Python library, and AI Hats for Raspberry Pi.
Potting and Encapsulation
Added a page on potting and encapsulation, covering the different types of potting compounds, conformal coating, and things to watch out for when potting electronics.
June 2026 Updates
HopeRF RFM69
Added info on the HopeRF RFM69 433/868/915 MHz RF transceiver.

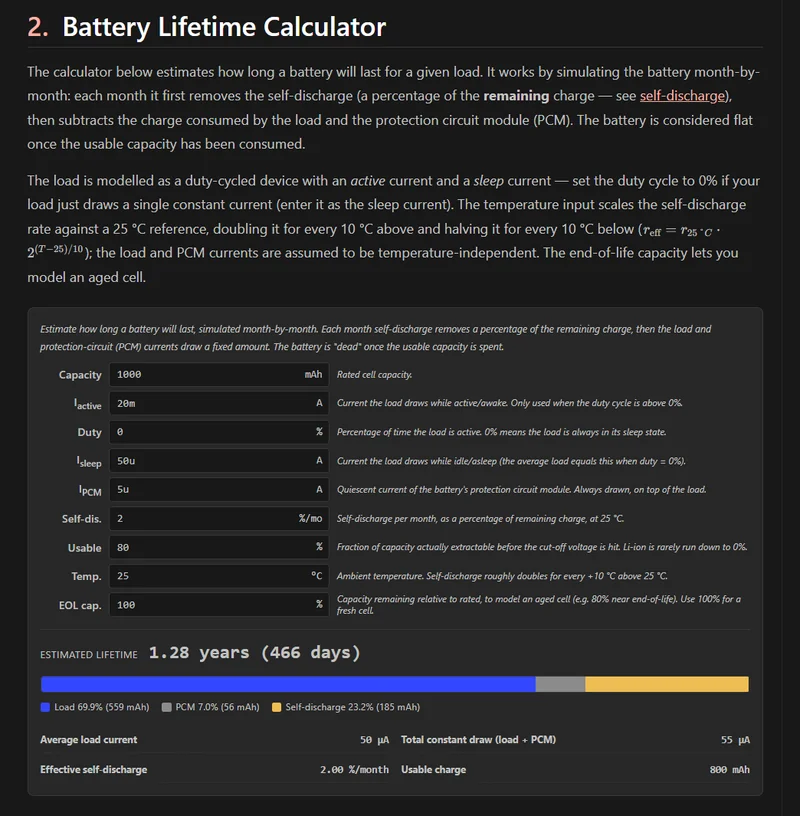
Battery Life Calculator
Added a battery life calculator to the Batteries page.
Hailo-8L AI Accelerator
Added info on the Hailo-8L AI accelerator processor.
STM32N6
Added info on the STM32N6 series of edge-AI MCUs and the NUCLEO-N657X0-Q development board.

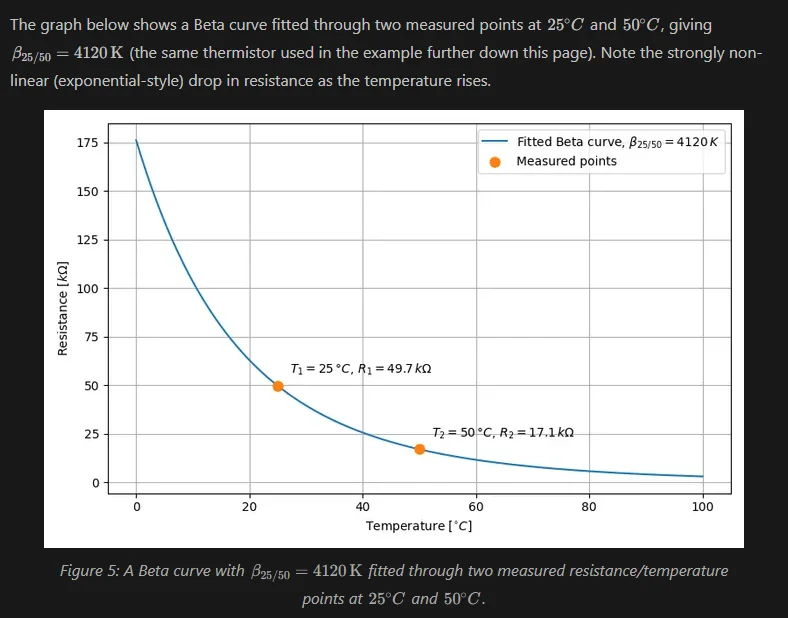
NTC Thermistor Beta Equation
Improved the Beta equation section on the temperature sensors page.
Bluetooth Low Energy
Add more info on the Bluetooth Low Energy (BLE) protocol including the packet format, PDU types, advertising diagrams, whitening, shorter connection intervals, frame space update and more.

Bluetooth Sniffing
Added info on how to sniff Bluetooth packets using Wireshark and Nordic Semiconductor nRF hardware BLE radios such as the nRF52840 dongle or nRF52 DK.
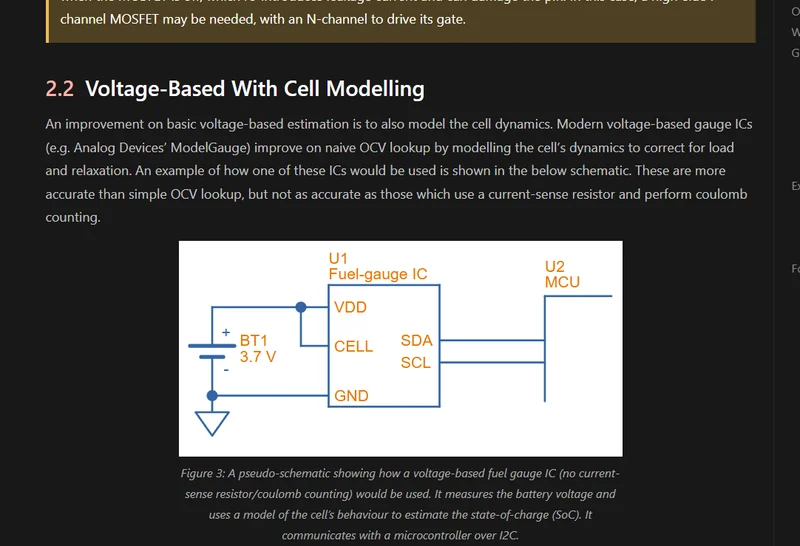
Fuel Gauge ICs
Added info on fuel gauge ICs including the gauging methods (voltage-based, coulomb counting and impedance tracking), key parameters such as state-of-charge (SoC) and state-of-health (SoH), and example ICs from TI and Analog Devices/Maxim.
Pelters
Added info on how raw PWM should not be used to drive Peltier devices.

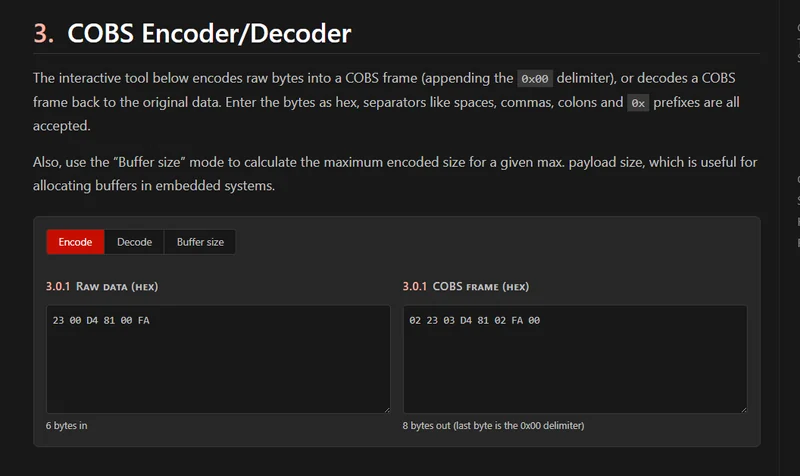
COBS
Added a COBS encoder/decoder tool to the COBS page.
May 2026 Updates
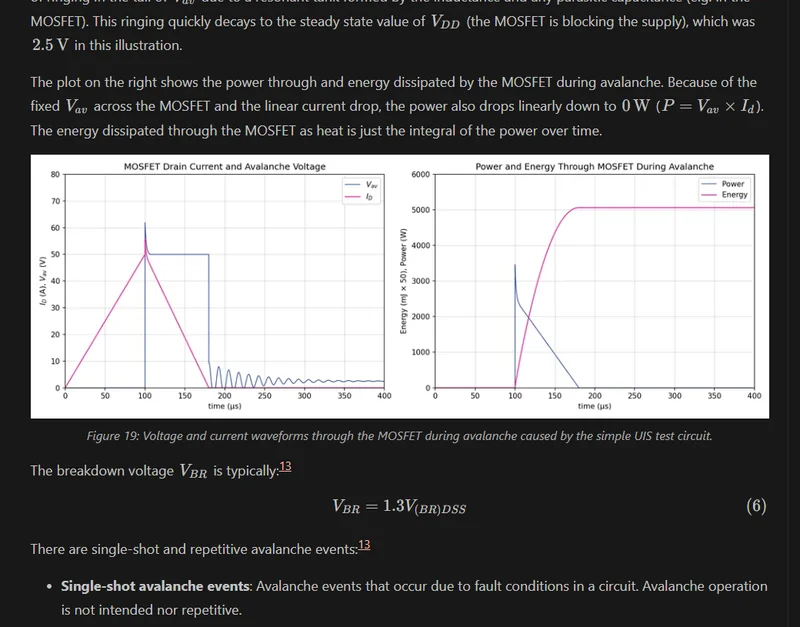
Avalanche Rated MOSFETs
Added info on Avalanche Rated MOSFETs.
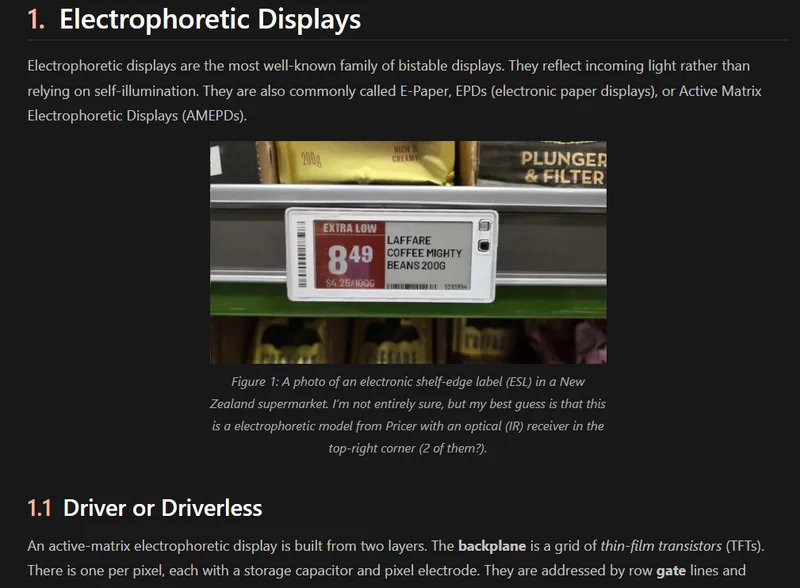
E-Paper Displays
Added info on E-Paper displays including Cholesteric Liquid Crystal Displays (ChLCDs).

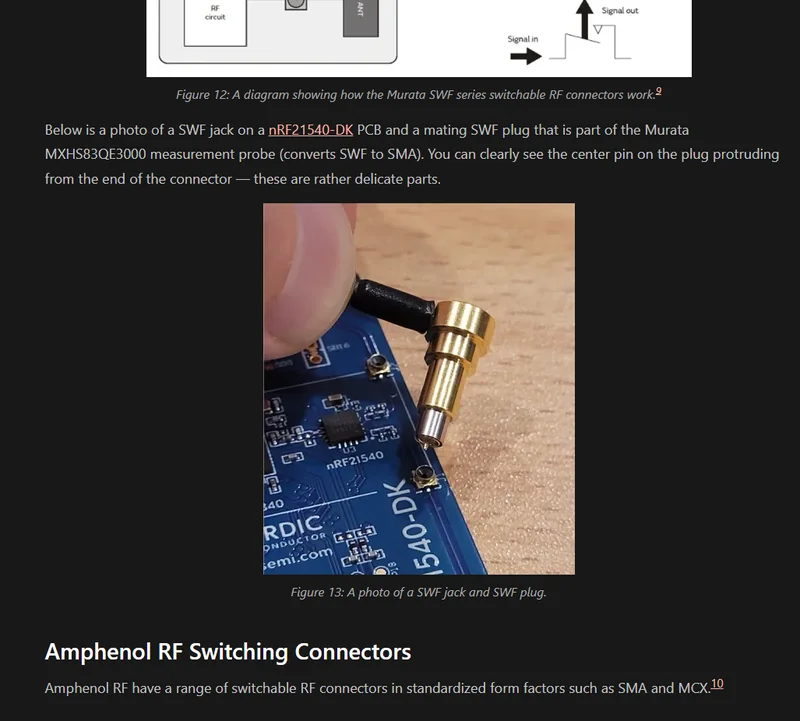
Switchable RF Connectors
Added info on switchable RF connectors.
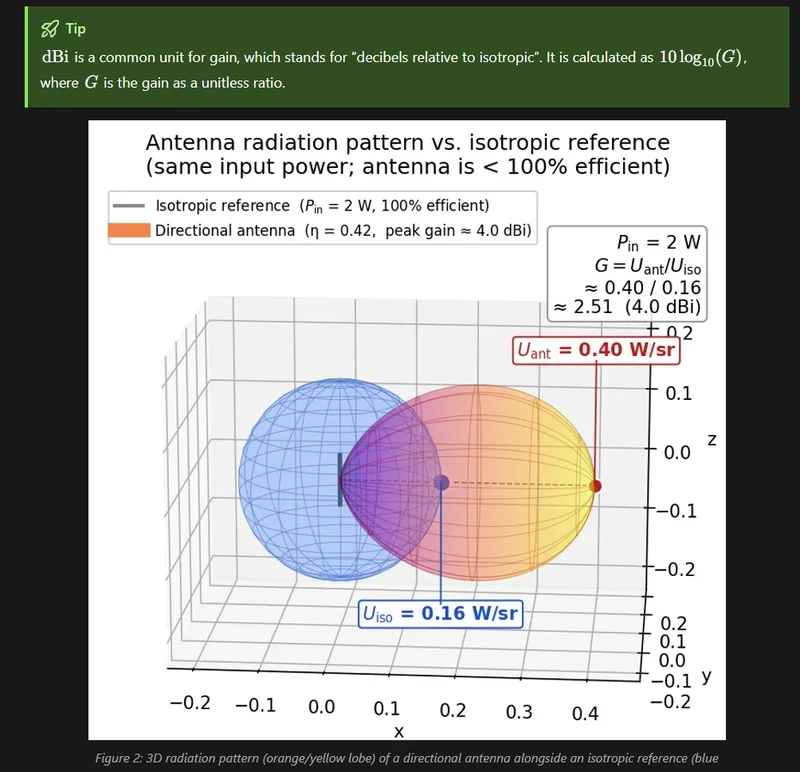
Antennas
Added info on antenna gain, a 3D plot showing the gain of a directional antenna compared to an isotropic antenna, and more to the antennas page.
Test Jigs
Added info on test jig architecture to the test jig page.
Stackable Banana Connectors
Added info on stackable banana connectors to the Tools page.
Bluetooth Range Extenders
Add info on the nRF52840 Bluetooth range extender (FEM) to the Bluetooth page.

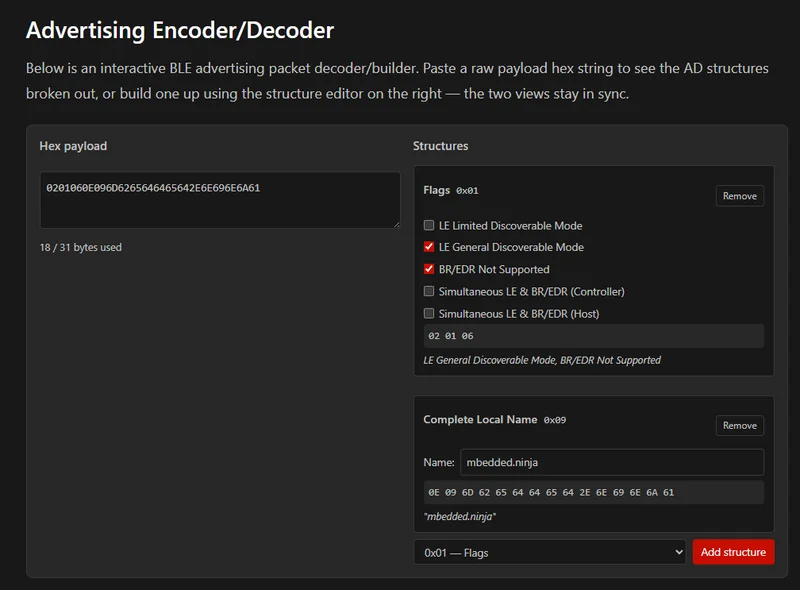
Bluetooth Advertising Data Encoder/Decoder
Added a bluetooth advertising data encoder and decoder to the Bluetooth page. This can take the raw hex advertising packet and decode it into the various structures, or build up the hex from the user describing the structures (e.g. Flags, Complete Local Name, Manufacturer Specific Data).
Resistor E Series Finder
Added an interactive E series resistor finder to the Resistors page. Enter a desired resistance and the widget shows the closest preferred value (and the closest equal-or-lower / equal-or-higher value) in each of the E6, E12, E24, E48, E96 and E192 series, along with the percentage error for each. Inputs accept metric prefixes (e.g. 10.3k, 2M2, 470R).
Resistors In Series/Parallel Calculator
Added an interactive parallel resistance calculator to the Resistors page.
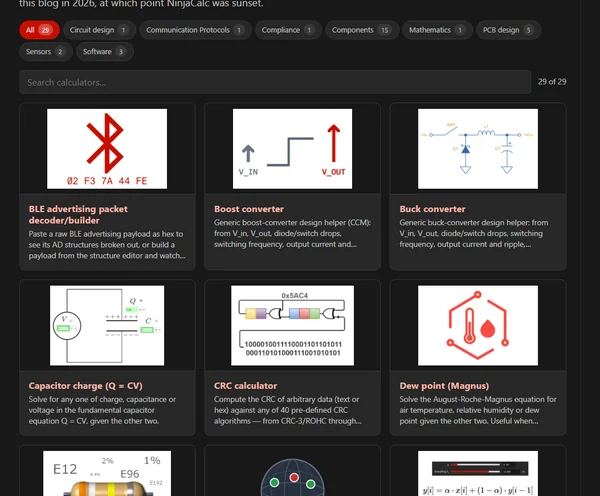
Ported NinjaCalc Calculators
Given I was starting to add specific calculators to certain pages, it made no sense to separately maintain NinjaCalc. I felt it was better to embed calculators around the textual information that provides background information and useful tips. And I felt I could still recreate the NinjaCalc “homepage” experience by creating a “Calculators” page which shows all of the available calculators on the site (click one takes you to the place in the page it is embedded in).
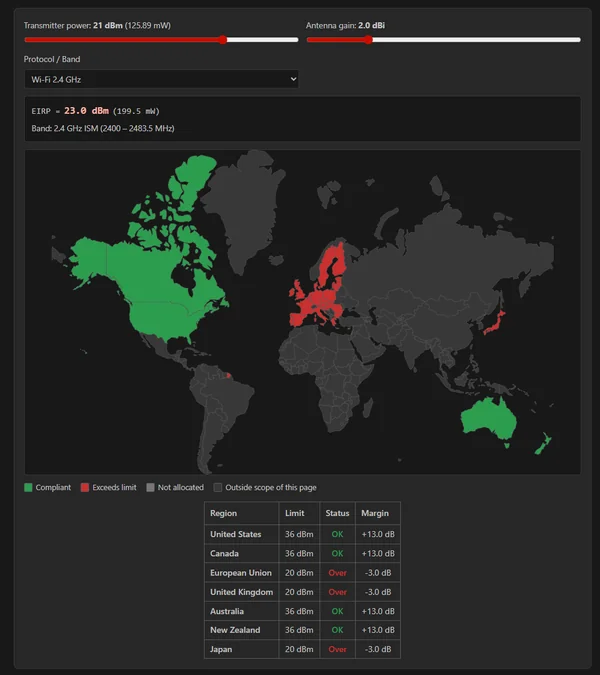
RF Spectrum Regulations Page
Added a new RF Spectrum Regulations page under the Compliance section.
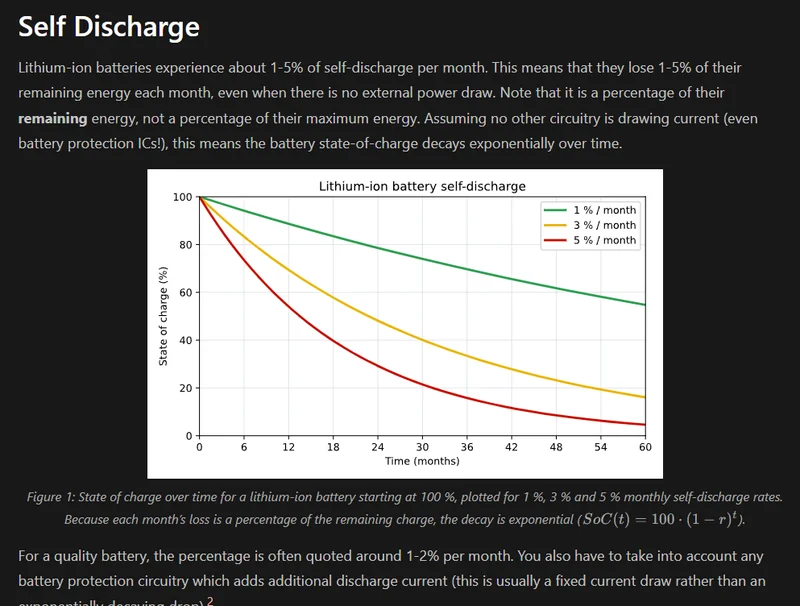
Lithium-ion Self-Discharge
Added info on Lithium-ion self-discharge.
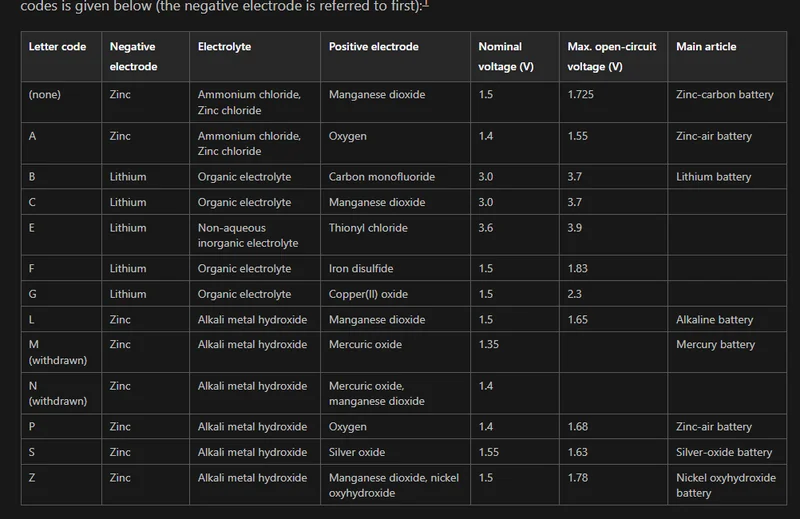
Coin Cell Batteries
Added info on coin cell battery codes and titanium alloy coin cells to the Coin Cells page.
April 2026 Updates
Added Info on the PFF, PSF and PSS Leadform Component Packages
Added info on the PFF, PSF and PSS leadform component packages.

Added Info on Component Packages
Added info on the following component packages:
- LFPAK component package.
- SOT-227 component package.
- TO-126 component package.
- TSOP component package.
Added Info on the Digilent Analog Discovery Pro
Added info on the Digilent Analog Discovery Pro MSO family.

Added Info on the Microchip EV02N47A LAN8770M Converter Board
Added info on the Microchip EV02N47A LAN8770M Converter Board.

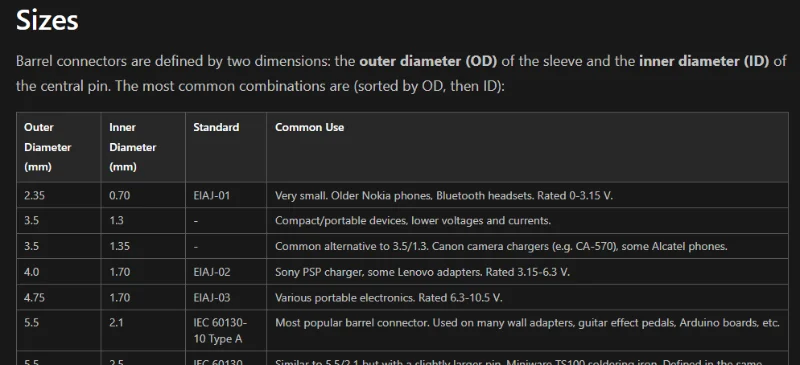
Added Info on Barrel Connectors
Added info on Barrel Connectors.
Added Info on Heat Set Inserts
Added info on Heat Set Inserts.

Added Info on Pressure Sensing Film
Added info on Pressure Sensing Film.

Added Info on Single Pair Ethernet (SPE)
Added info on Single Pair Ethernet (SPE).
Added Info on Load Cells
Added info on Load Cells.
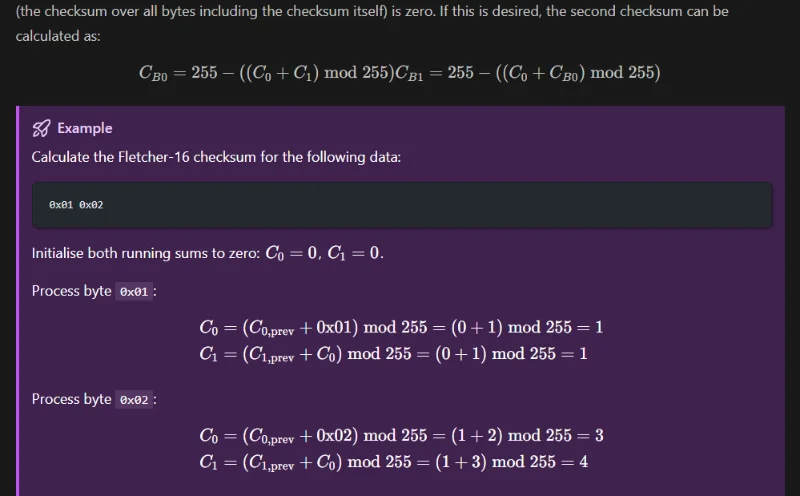
Added Info on Fletcher’s Checksum
Added info on Fletcher’s Checksum.
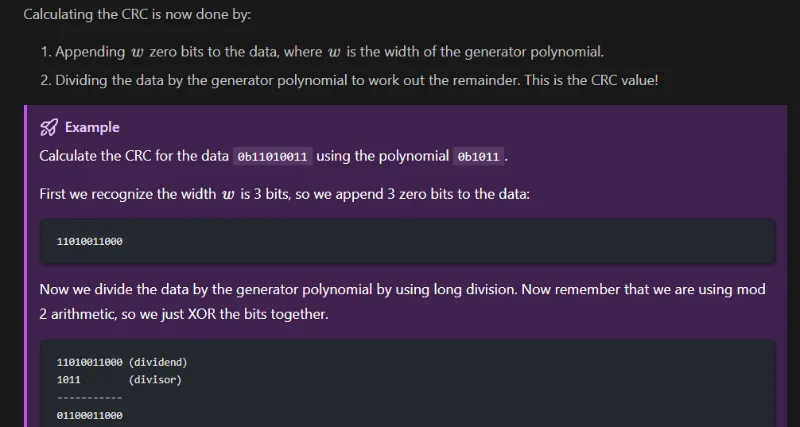
Added Info on CRCs (Cyclic Redundancy Checks)
Added info on CRCs (Cyclic Redundancy Checks).
March 2026 Updates
Added Info on Executing Code from RAM Instead of Flash
Added info on executing code from RAM instead of flash to the Low Power Design page.

Added Info on DIN Mounted Terminal Blocks
Added info on DIN mounted terminal blocks to the Terminal Blocks page.

Added Info on the Fibox EK Series Enclosures
Added info on the Fibox EK series enclosures to the Enclosures page.

Added Info on DIN Mounted Isolated SMPS
Added info on DIN mounted isolated SMPS to the Isolated Switch Mode Power Supplies page.
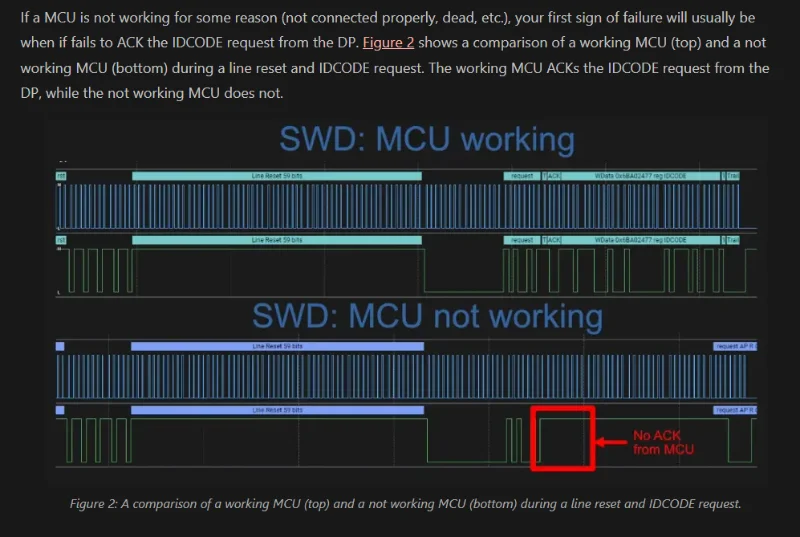
Added Info on the SWD Protocol
Added info on the SWD protocol to the Programming Microcontrollers an Overview page.
February 2026 Updates
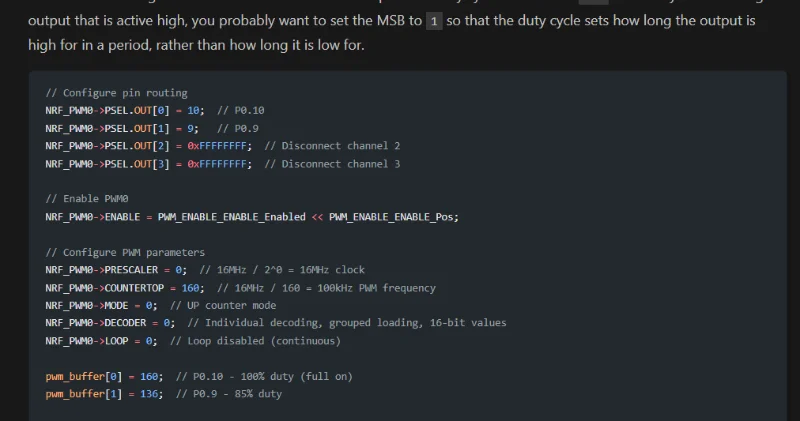
Added Info on various nRF52 Peripherals
Added info on various peripherals on the nRF52 series including the GPIO, PWM, timer/counter (TIMER), and watchdog timer (WDT).
Added Info on Enclosures
Added info on enclosures.

Moved Info on Terminal Blocks Onto It’s Own Page
Info on terminal has been moved to it’s own page here.
January 2026 Updates
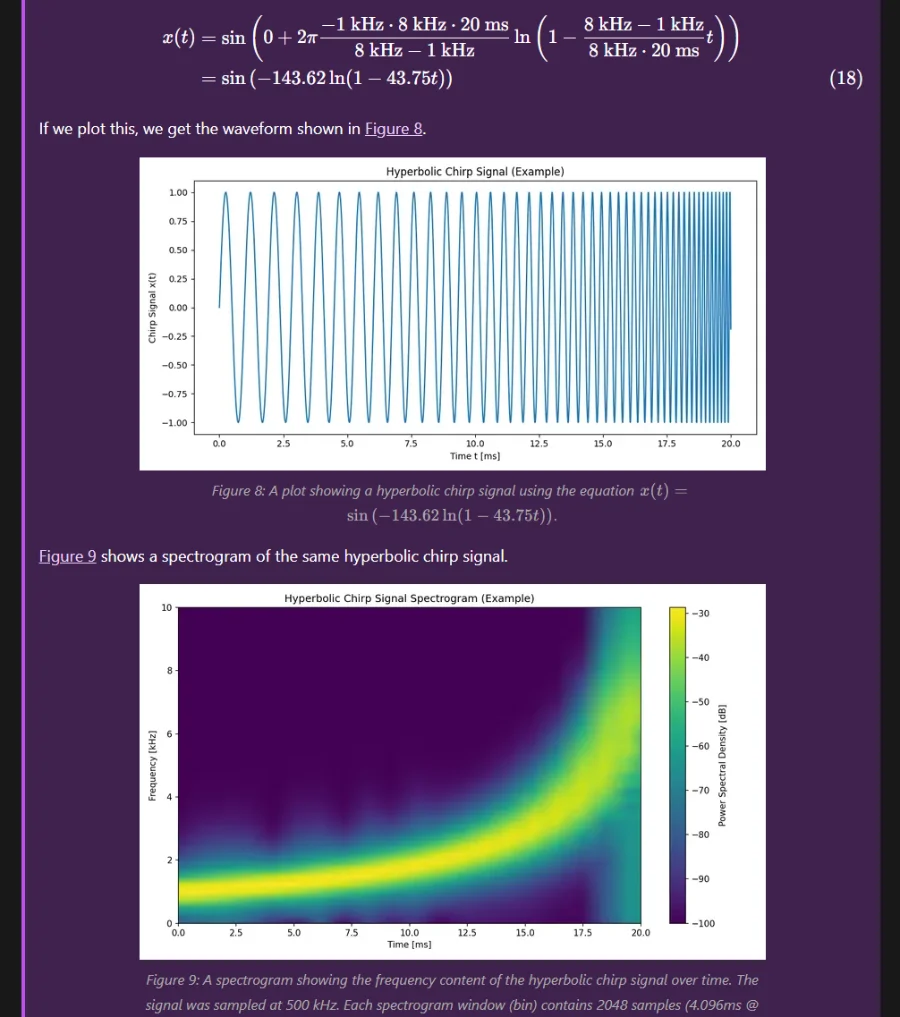
Added Info on Chirps
Added info on chirps.
Added Info on Power Management ICs
Added info on power management ICs.
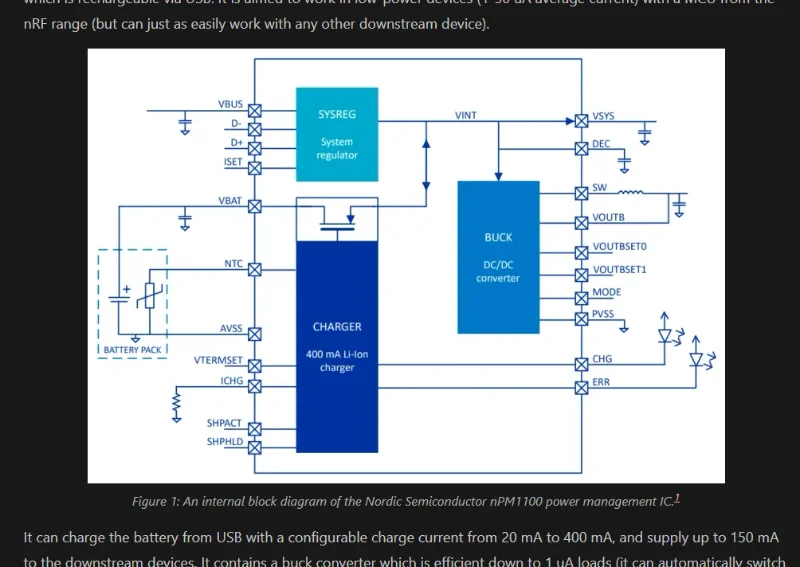
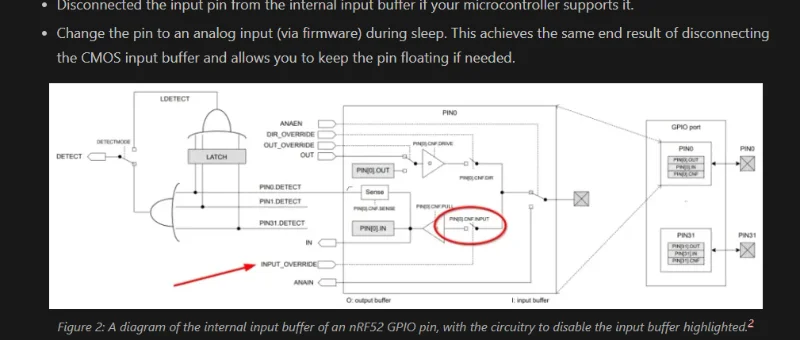
Added Info on Low Power Design
Added info on keeping digital inputs in defined states during sleep in low power design.
Added Info about the nRF52 QSPI Driver
Added info about the nRF52 QSPI driver.
Added Info on Pressure Sensors
Added info on pressure sensors.
Added Info on pySerial
Added info on pySerial, a popular Python library for serial communication.
Added Info on Sallen-Key Filters in Ableton Live
Added info on Sallen-Key filters in Ableton Live.
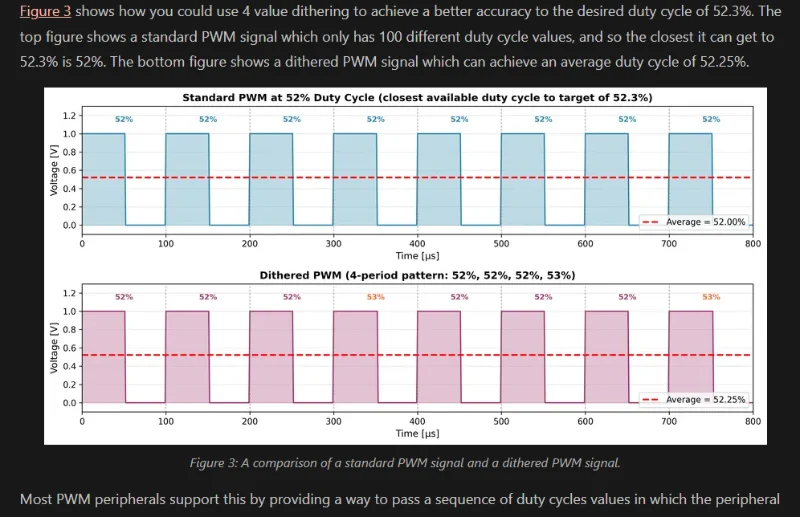
Added Info on PWM Dithering
Added info on PWM dithering.
Happy New Year 2026
2025 saw 282k (282,000) page views for blog.mbedded.ninja. This is down from 505k last year, a decrease of 223k or 44%. That’s quite the drop! AI is the likely culprit, with less people visiting the site due to just using AI to answer technical embedded engineering questions, and AI powered search summaries (i.e. the one Google uses) which means the user does not need to visit the site. This is a placeholder for the reference: fig-stats-graphs shows the page views and other key stats per year.
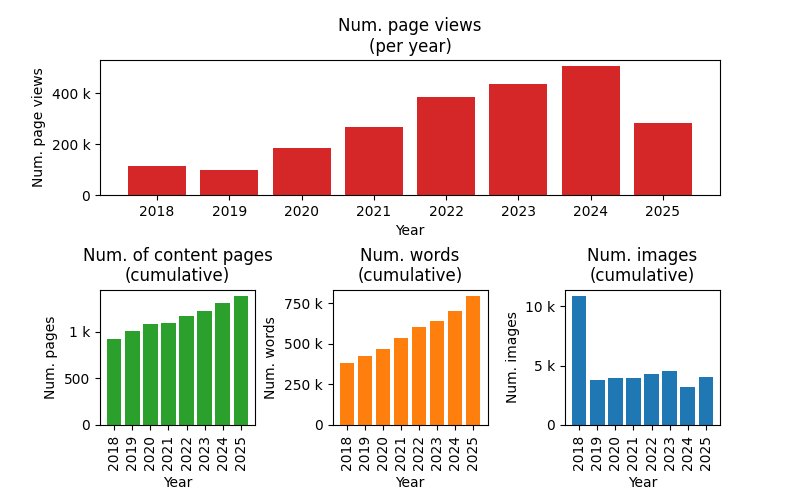
NinjaTerm went through 11 releases from v4.19.0 to v5.8.2 during 2025. This includes the jump to v5 which is a major change from being a web app to an Electron-based desktop app. It has 101 stars on GitHub and the app was started (based of the custom app_start event in Google Analytics) 3.2k times (since v5.0.0 was released).
NinjaCalc went through no new releases in 2025. It has 34 stars on GitHub and had 51k page views (as reported by Google Analytics).
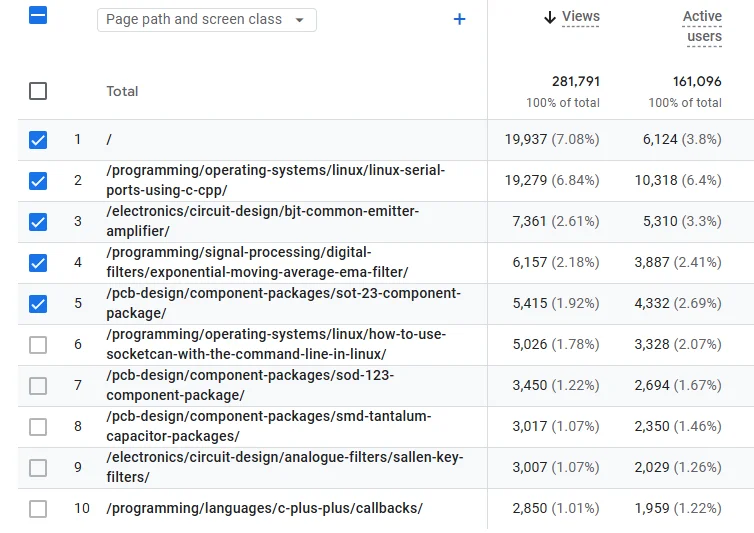
Most Popular Blog Pages
This is a placeholder for the reference: fig-engagement-pages-and-screens shows the top 10 most popular pages, ranked by number of page views.
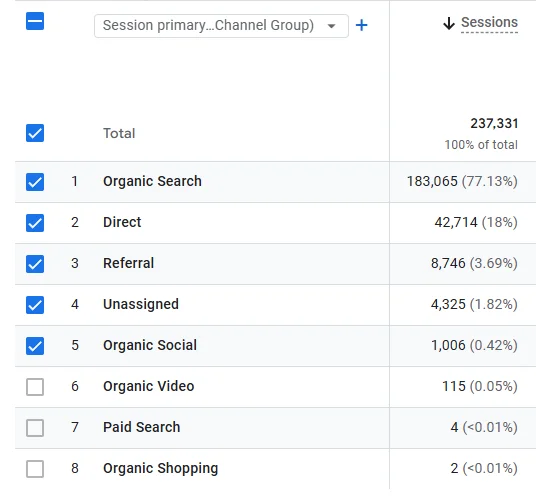
Blog Acquisition
This is a placeholder for the reference: fig-traffic-acquisition shows the top 7 sources of acquisition traffic in 2025. As usual, most of the traffic was from organic search (e.g. Google search engine).
Blog Word, Page and Image Counts
At the end of 2025 the site had 794k words, up from 704k words last year (an increase of 90k). These words were spread over 1382 pages (up from 1313 pages last year), and included 4,042 images (an increase of 820 from 3,222 images images last year). Note that I discovered a bug in the stats calculation code which was excluding .webp images from the total image count. I fixed this for the 2025 year, so the increase from last year will be inflated due to missed images in years prior.
Achievements in 2025
- NinjaTerm got a major update to v5, which is a major change from being a web app to an Electron-based desktop app. This allows for a more feature rich app as it is no longer restricted by the browser’s sandbox. This has allowed for improvements such as showing the user more serial port information, adding serial over BLE support, serial over socket support, and more.
Plans For The 2026 Year
- Add more content to the blog (as always!).
- Keep adding features to NinjaTerm.
December 2025 Updates
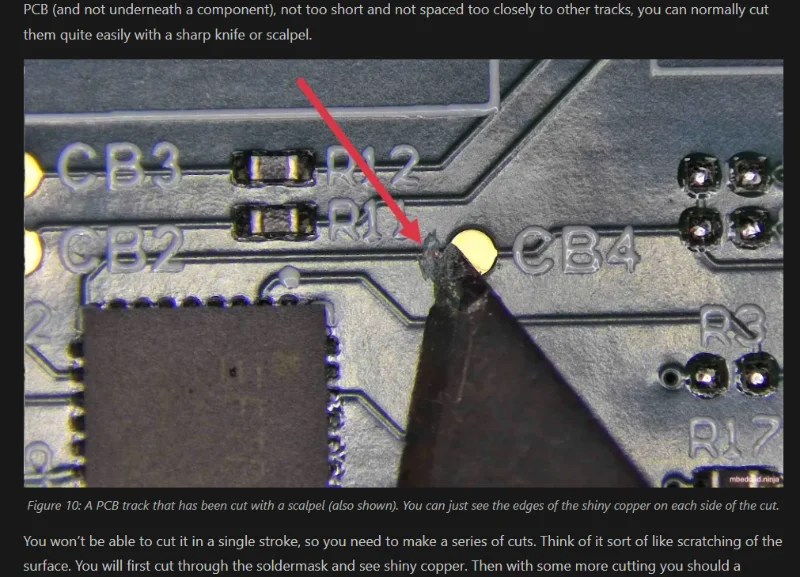
Cutting PCB Tracks
Added info on cutting PCB tracks to the PCB rework guide.
SSOP Component Package
Added info on the SSOP component package.

FTDI FT232RNQ
Added info on the FTDI FT232RNQ IC.

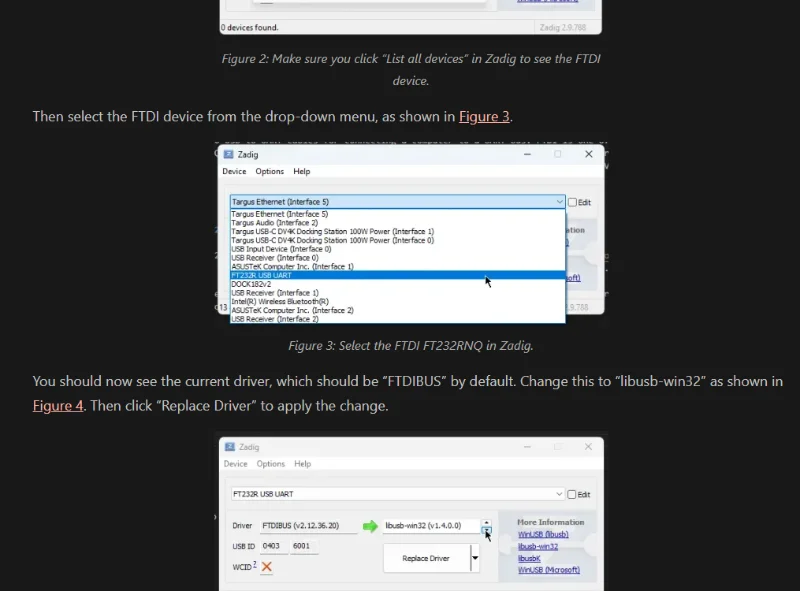
Controlling FTDI Devices
Added info on controlling FTDI devices from Python using the pyftdi library.
USB C Connectors
Added info on the USB C connectors and their PCB mounting orientations.
MSP430 Bootloader (BSL)
Added info on the MSP430 Bootloader (BSL) for the MSP430 microcontroller family.
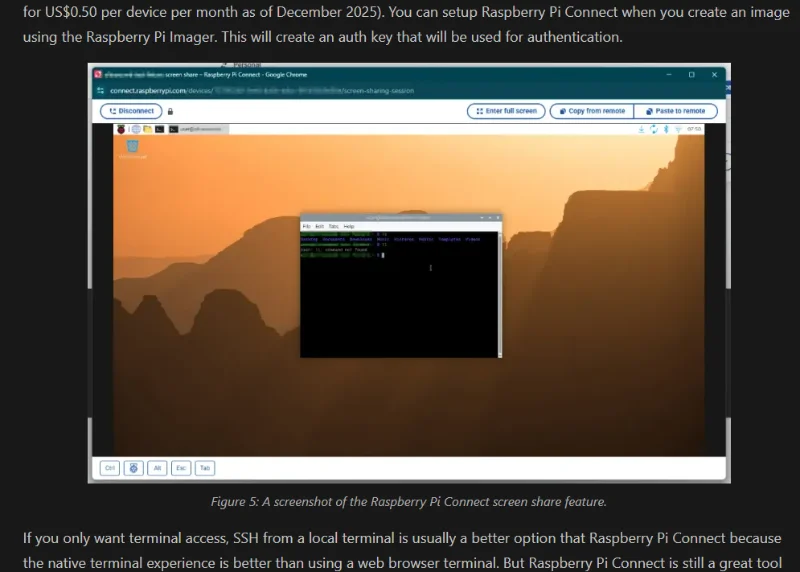
Raspberry Pi Connect
Added info on Raspberry Pi Connect for the Raspberry Pi.
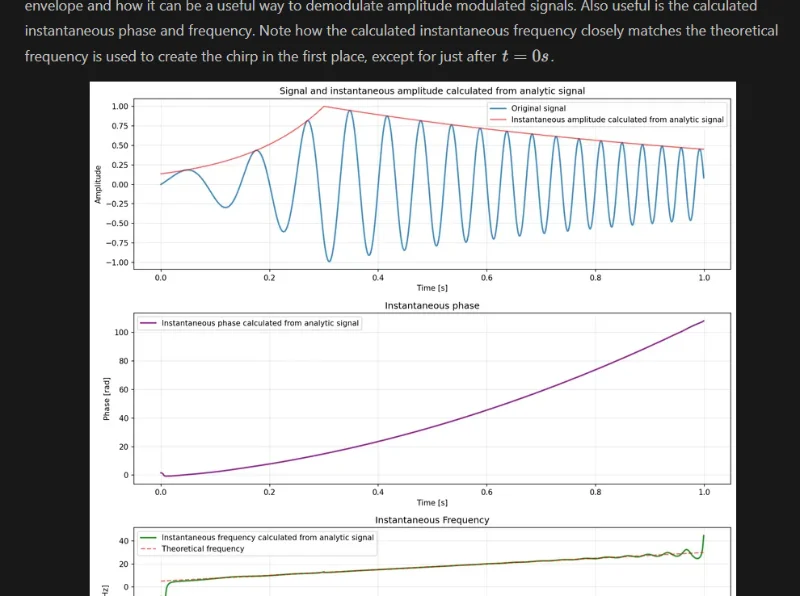
Analytic Signals and the Hilbert Transform
Added info on Analytic Signals and the Hilbert Transform.
nRF Connect Quick Start
Added info on the nRF Connect Quick Start tool for the nRF SoCs.
nRF Cloud
Added info on nRF Cloud.
November 2025 Updates
Logic Analysers
Added info on logic analysers, a tool for capturing and analysing digital signals.

ESP32-C6
Added info on the ESP32-C6 SoC.

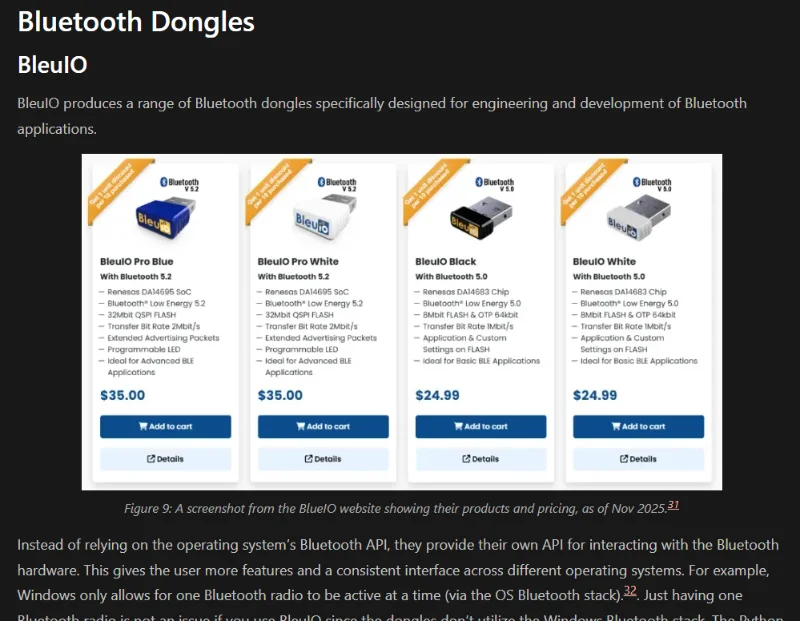
Bluetooth Dongles
Added info on Bluetooth dongles.
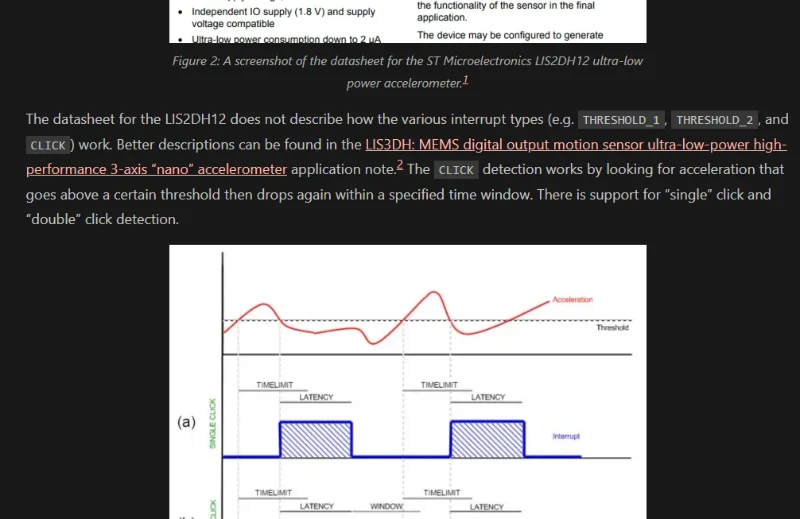
Accelerometers
Added info on low-power accelerometers.
October 2025 Updates
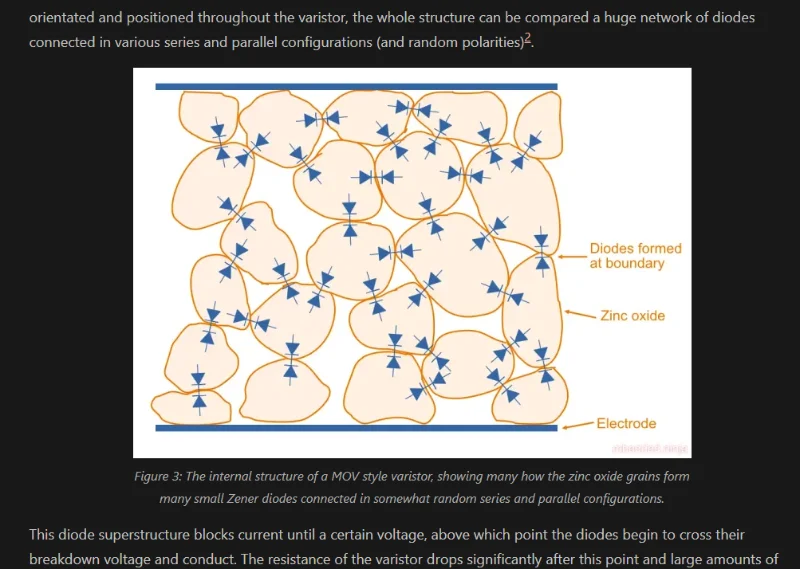
Varistors
Added more info on varistors, including the internal structure of a MOV style varistor and how they work.
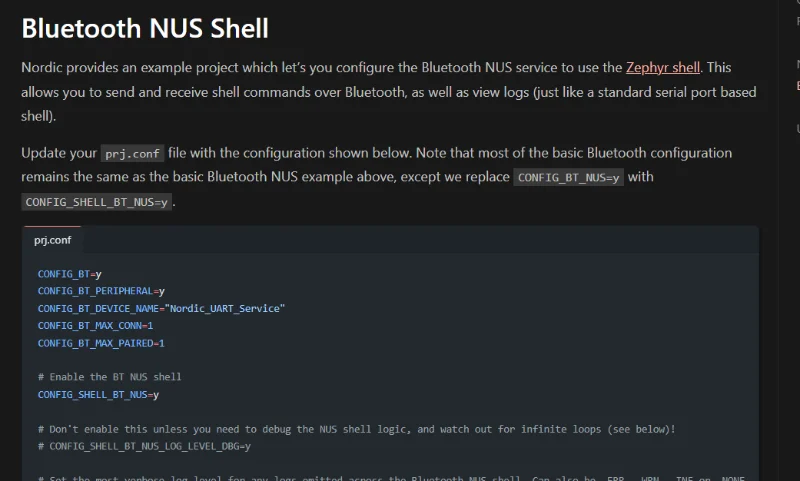
Zephyr Bluetooth NUS Shell
Added info on the Zephyr Bluetooth NUS shell.
Reed Relays
Added info on reed relays, a form of mechanical relay that uses a reed switch for the contacts.

High Voltage Resistors
Added info on high voltage resistors.
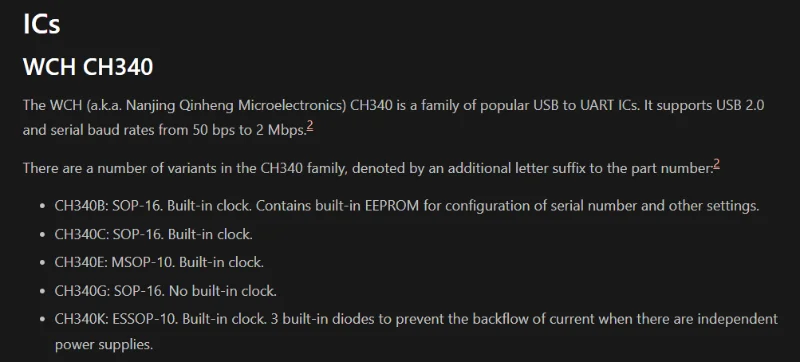
WCH CH340
Add info on the WCH CH340 family of USB to UART ICs.
How To Calibrate Sensors
Added info on how to calibrate sensors.
uv
Added info on uv, a popular tool for managing Python environments and dependencies.
Board Bring-Up
Added info on board bring-up, a process of testing a new PCB to ensure it is working correctly.
SEGGER J-Link
Added info on SEGGER J-Link, a tool for programming and debugging ARM microcontrollers.
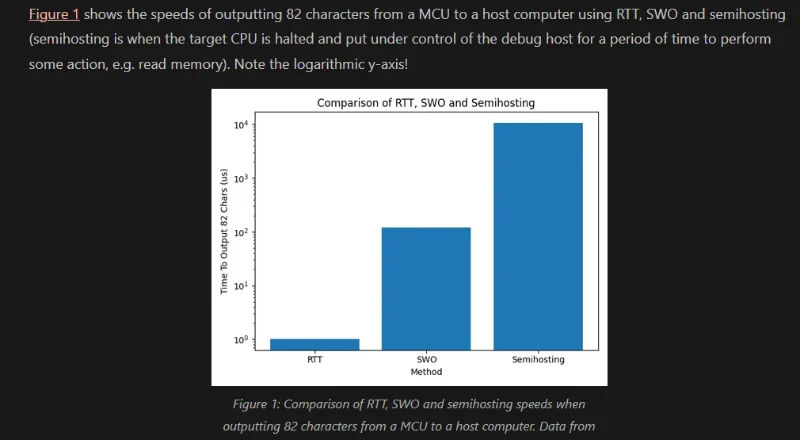
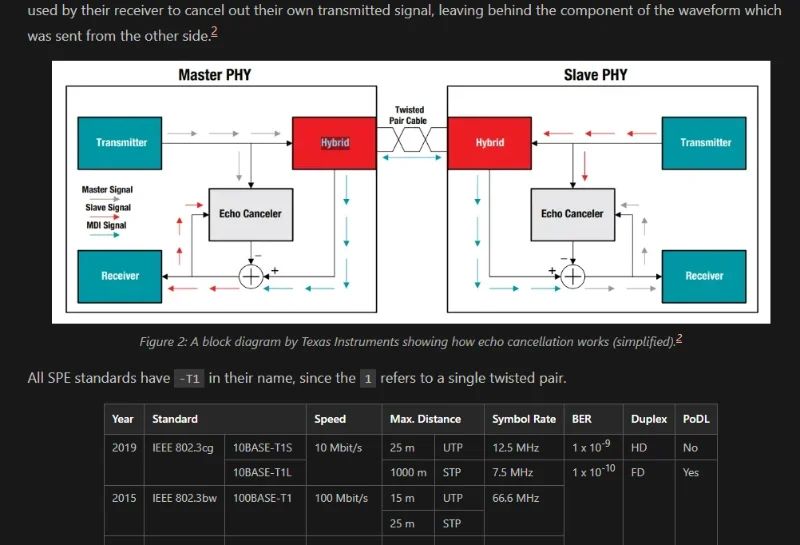
Single Pair Ethernet (SPE)
Added info on Single Pair Ethernet (SPE), a version of Ethernet which uses a single twisted pair.
TVS Diode Capacitance
Added info on how to reduce the capacitance of high power TVS diodes by adding general purpose diodes in series.
September 2025 Updates
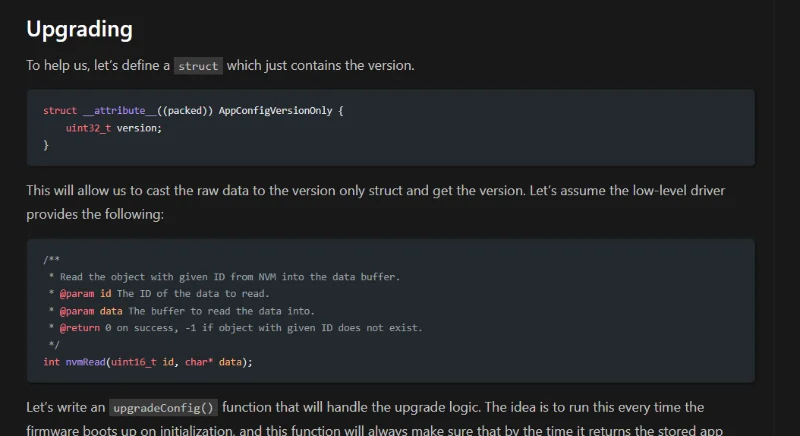
Application Config Tutorial
Added a new tutorial on how to manage and upgrade application config stored in non-volatile memory in an embedded system.
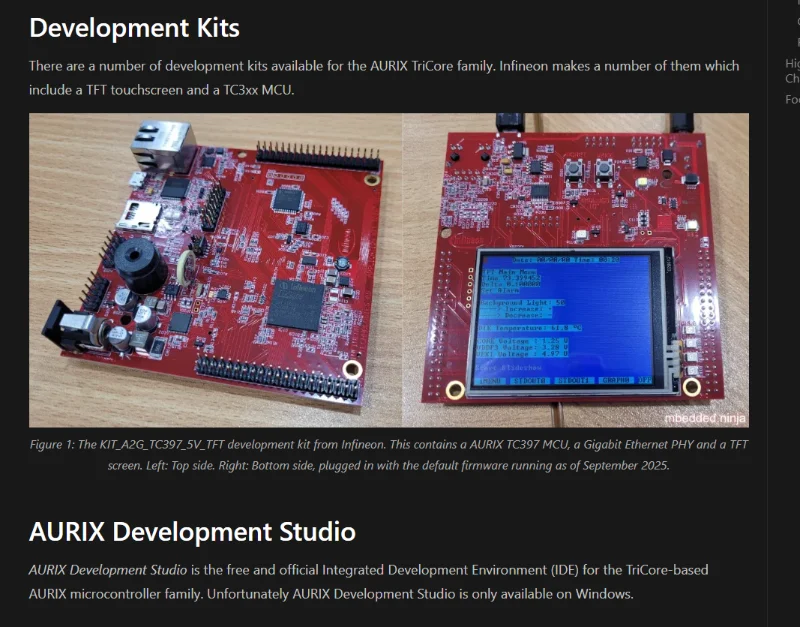
Infineon AURIX TriCore
Added more information on the Infineon AURIX TriCore MCUs.
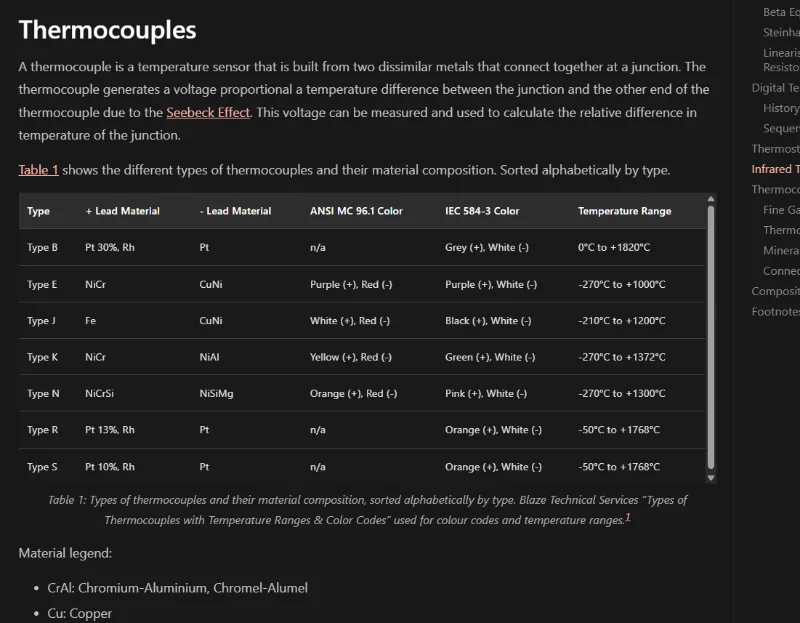
Thermocouples
Added info on thermocouples to the Temperature Sensors page.
IoT Pairing Methods
Added info on IoT pairing methods to the IoT Pairing Methods page.

Ultra-wide Band (UWB)
Added info on Ultra-wide Band (UWB).
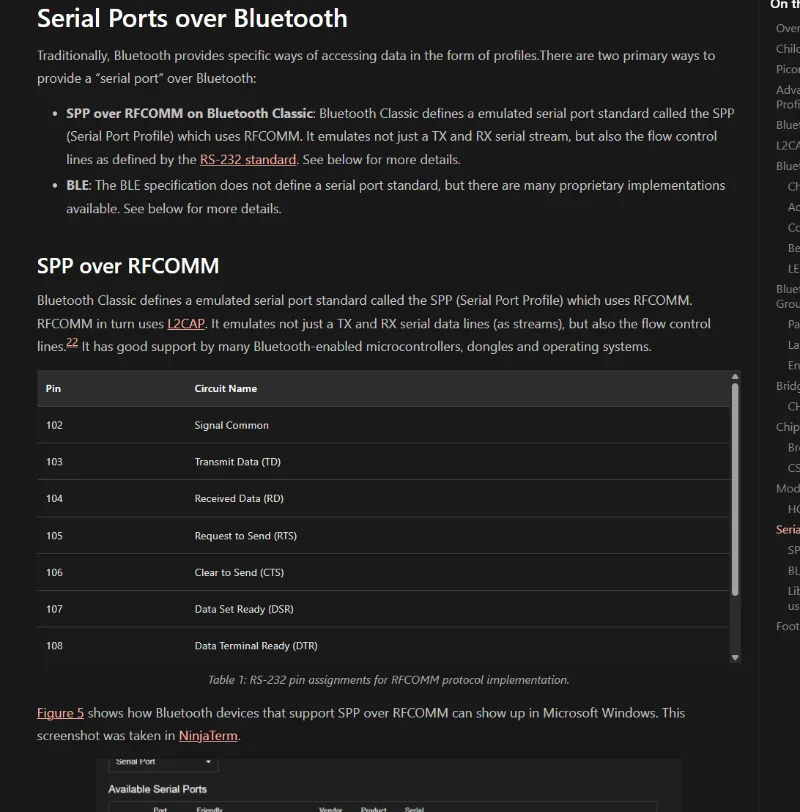
Serial Ports over Bluetooth
Added info on virtual serial ports over Bluetooth to the Bluetooth page, including the SPP protocol over RFCOMM for Bluetooth Classic, and the various proprietary virtual serial port protocols for Bluetooth Low Energy (BLE).