A Comparison Of Serialization Formats

When you want to save, send or receive data passed around in applications, there are many different serialization formats to choose from. What is the best choice for your use case? This page aims to help answer this question by comparing some of the most popular serialization formats used today.
The following serialization formats will be reviewed:
- CSV
- JSON
- Protobuf (Protocol Buffers)
- TOML
- XML
- YAML
Lets begin with a disclaimer: There is no one-size-fits-all serialization format --- the best format for the job depends on things such as the type/amount of data that is being serialized and the software that will be reading it.
The examples in the following sections show how different formats store the same data. I chose a simple, repeatable data structure which was supported by all reviewed serialization formats (two Pokemon objects, each of which had id, name, age and address fields). Note that many of these serialization formats can store non-repeatable, randomly structured data (in fact, all can except CSV), so in a way I am tailoring to the lowest common denominator, which influences the results.
In each review section, a score between 1-3 is highlighted red, 4-6 orange, and 7-10 green.
CSV
CSV is well suited to storing large amounts of tabulated data in a human-readable format. It is not well suited to storing objects or hash table like data structures (unlike every other serialization format that is reviewed here).
CSV is not very well standardized. RFC 4180 was an attempt to standardize the format, however the name “CSV” may refer to files which are delimited by non-comma characters such as spaces, tabs or semi-colons. In fact, CSV is really just one member of the more general family of Delimiter Separated Values (DSV) formats, although CSV seems like the more prevalent term these days. And the format of the data between the delimiters is completely user defined (e.g. there is no specified way of defining dates).
The CSV format allows an optional header line appearing as the first line in the file. If present, it contains field names for each value in a record. This header line is very useful for labelling the data and should almost always be present.
The CSV format is well supported, with CSV libraries available for almost every popular programming language. The popular data manipulation library pandas for Python can read in a CSV straight into a data table (called a DataFrame) with a simple one-line command of pd.read_csv('myfile.csv'). CSV is also really the only serialization format reviewed on this page which has good support in spreadsheet programs such as Excel (it is the only serialization format reviewed which makes sense to be read into Excel, as CSV enforces a tabular structure).
For a human-readable format, CSV is quite concise (see the File Size section for more info). However, it can be difficult to work out what column is what, especially when there are a large number of rows (there is only one header row right at the top of the file), there are a large number of columns (there is no requirement of the columns being equal-spaced, and so you end up counting the commas from the left), and/or if there are empty fields (i.e. ,,).
Example
id, name, age, address4, Charmander, 12.34, Fire Street25, Pikachu, 56.78, Electric StreetReview
| Property | Value | Comment |
|---|---|---|
| Brevity | 9/10 | With only commas separating values, CSV is very concise for a human-readable format. |
| Human Readability | 5/10 | CSV is readable, although it is easy to get lost within a row with a large amount of data. |
| Language Support | 9/10 | CSV has wide support and is readable in almost every major language (and if there is no support, it is really easy to write a parser yourself!). Spreadsheet programs also love CSV files. |
| Data Structure Support | 3/10 | CSV only supports tabular/array-like data. It does not support dictionary/map-like data, nor relational data. |
| Speed | 10/10 | CSV is very fast to serialize/deserialize. When serializing/deserializing 10,000 small objects, CSV beat even Protobuf in Python, and was a close second to Protobuf in C++. See the Speed Comparison section for more info. |
| Standardization | 3/10 | CSV is not well standardized. |
JSON
JSON is a ubiquitous human-readable data serialization format that is supported by almost every popular programming language. JSON’s data structures closely represent common objects in many languages, e.g. a Python dict can be represented by a JSON object, and a Python list by a JSON array. Note there are caveats to this!
It is important to note that the JSON syntax does not support comments! This can be a blessing (but mostly a curse). For large amounts of data that get read into software and written back to disk, comments would be pretty much useless anyway because they would not be preserved when re-written to file. If you do need comments, the common workaround is to add a __comment__ name/value pair or similar to JSON objects. The name in a JSON object’s name/value pairs always has to be a string. It also does not support any type of date format.
Example
[ { "id": 4, "name": "Charmander", "age": 12.34, "address": "Fire Street" }, { "id": 25, "name": "Pikachu", "age": 56.78, "address": "Electric Street" }]Review
| Property | Value | Comment |
|---|---|---|
| Brevity | 7/10 | JSON has concise syntax, although not as concise as YAML and TOML in most situations. |
| Human Readability | 5/10 | JSON is human-readable. It loses some marks because it does not support comments. |
| Language Support | 9/10 | JSON has very good language support. |
| Data Type Support | 6/10 | JSON supports array and map (object) structures. It supports many different data types including strings, numbers, boolean, null, etc., but not dates. |
| Speed | 9/10 | JSON is one of the fastest human-readable formats to serialize/deserialize that I reviewed. See the Speed Comparison section for more info. |
| Standardization | 9/10 | JSON has an official standards body. See https://www.json.org/. |
Protocol Buffers (Protobuf)
Protobuf is a binary serialization protocol developed by Google. Since it serializes to binary, it is not human readable (although you can still pick out strings when viewing the file as ASCII text, see the example below).
The types of data that Protobuf can contain are well defined and include common types such as strings, integers and floats, with dates/times supported via the Timestamp well-known type.
Example
#^R^Charmander^Z^Fire Street%<A2>@^A^R^Pikachu^Z^Electric Street%<F1>'OAReview
| Property | Value | Comment |
|---|---|---|
| Brevity | 9/10 | Protobuf, being a binary format, is very concise. It also uses variable-bit encoding for data types such as integers to reduce the number of bytes when the numbers are small. Would get 10/10 if it implemented some type of compression scheme. |
| Human Readability | 1/10 | Protobuf is not designed to be human-readable. |
| Language Support | 7/10 | Protobuf supports C, C++, C#, Dart, Go, Java, Objective-C, PHP, Python and Ruby. |
| Data Type Support | 8/10 | Protobuf allows you to define data structures in .proto files. Protobuf supports many basic primitive types, which can be combined into classes, which can then be combined into other classes. |
| Speed | 9/10 | Protobuf is very fast, especially in C++ (relative to other serialization formats). See the Speed Comparison section for more info. |
| Standardization | 9/10 | Protobuf is standardized by Google. |
TOML
TOML (Tom’s Obvious, Minimal Language) is a newer (relative to the others in this review) human-readable serialization format. It is quite similar to YAML in that it is aimed towards configuration files, but it strives to be a simpler format (YAML can get quite complex, and this can be seen in the much slower YAML parse times).
TOML has syntax highlighters for Atom, Visual Studio, Visual Studio Code and other IDEs.
TOML suffers from somewhat verbose syntax when it comes to expressing an array of objects (or in TOML speak, an array of tables). This can be seen in the example below where each pokemon object in the array is delimited with [[pokemon]].
Example
[[pokemon]]id = 4name = "Charmander"address = "Fire Street"age = 12.34
[[pokemon]]id = 25name = "Pikachu"address = "Electric Street"age = 56.78Review
| Property | Value | Comment |
|---|---|---|
| Brevity | 7/10 | TOML is quite concise, except for when it comes to arrays of tables. |
| Human Readability | 9/10 | One of TOML’s primary goals was to be very easy to understand. |
| Language Support | 6/10 | TOML is a relatively new serialization format and does not have the same number of libraries as say JSON, CSV or XML for various programming languages. |
| Data Type Support | 9/10 | TOML supports most common types of data including strings, integers, floats and dates. TOML does not support references like YAML does (probably because TOML aims to be simple). |
| Speed | 6/10 | TOML is on the slower end of the spectrum, but is faster than YAML. See the Speed Comparison section for more info. |
| Standardization | 9/10 | TOML is well standardized. |
XML
XML is a human-readable serialization protocol. A well known XML-like format is HTML which is used to determine the structure of web pages.
One disadvantage of XML is its verbosity. Its descriptive end tags, which require you to re-type the name of the element that is being closed, add to the byte count of XML data.
It is well standardized, with plenty of tooling available to generate XML and validate it with schemas. The specification for XML can be found at https://www.w3.org/TR/xml/.
XML supports both standard (DOM style) parsers and streaming (SAX style) parsers.
Example
<pokemon_list> <pokemon> <id>4</id> <name>Charmander</name> <age>12.34</age> <address>Fire Street</address> </pokemon> <pokemon> <id>25</id> <name>Pikachu</name> <age>56.78</age> <address>Electric Street</address> </pokemon></pokemon_list>Review
| Property | Value | Comment |
|---|---|---|
| Brevity | 3/10 | XML is not known for being short and sweet. |
| Human Readability | 5/10 | Human-readable, although you can get lost in-between all the tags in-front of your eyes. |
| Language Support | 9/10 | Supported in all major languages, usually with built-in libraries. |
| Data Type Support | 9/10 | XML is very flexible as each element can have attributes and arbitrary child elements. |
| Speed | 8/10 | XML is quite fast. In Python it was slower to parse than JSON, although in C++ it was slightly faster. See the Speed Comparison section for more info. |
| Standardization | 10/10 | XML is standardized by the W3C. W3C also recommends the use of the XSD (XML Schema Definition, also referred to as WXS) as the primary schema for use with XML. |
YAML
YAML (YAML Ain’t Markup Language) is a human-readable serialization format that is popular for configuration files.
The YAML specification is much larger than the JSON specification. YAML allows for relational data (references) using anchors (&) and aliases (*). YAML gets some bonus style points since the YAML homepage is even displayed in YAML (https://yaml.org/).
YAML (as of v1.2) is a super-set of JSON (with a few minor caveats), which means you can parse JSON with a YAML parser (the YAML parser will probably take longer though, so don’t use this trick with large amounts of JSON data!).
Example
- { id: 4, name: Charmander, age: 12.34, address: "Fire Street" }- { id: 25, name: Pikachu, age: 56.78, address: "Electric Street" }Review
| Property | Value | Comment |
|---|---|---|
| Brevity | 9/10 | Values can default to strings, allowing you to omit quote marks. It has terser syntax than TOML for arrays of objects (in TOML you have to precede each element with [[array_name]]). |
| Human Readability | 7/10 | Basic YAML is really easy to read, however YAML’s complexity can confuse a reader when using its advanced features. |
| Language Support | 6/10 | YAML is popular enough for there to be libraries for most popular languages, but it is not as ubiquitous as CSV or JSON. |
| Data Type Support | 10/10 | YAML supports most common types of data including strings, integers, floats and dates. YAML even supports references (relational data) and external data! |
| Speed | 2/10 | YAML showed the slowest serialization/deserialization runtimes out of any format I tested, in both C++ and Python (see the Speed Comparison section for more info). |
| Standardization | 8/10 | YAML is well standardized, but it can be hard to find extra functionality such as schema validators (I have had to reach for jsonschema to validate YAML). |
Speed Comparison (Benchmarking)
The following libraries were used for the speed comparison tests:
| Format | Python | C++ |
|---|---|---|
| CSV | csv (built-in) | fast-cpp-csv-parser (https://github.com/ben-strasser/fast-cpp-csv-parser) |
| JSON | json (built-in) | json (https://github.com/nlohmann/json) |
| Protobuf | protobuf (https://github.com/protocolbuffers/protobuf) | protobuf (https://github.com/protocolbuffers/protobuf) |
| TOML | toml (https://github.com/uiri/toml) | cpptoml (https://github.com/skystrife/cpptoml) |
| XML | ElementTree (built-in) | tinyxml2 (https://github.com/leethomason/tinyxml2) |
| YAML | PyYAML (https://pyyaml.org/) | yaml-cpp (https://github.com/jbeder/yaml-cpp) |
Python v3.7 was used for all Python tests. C++17/GCC compiler was used for all C++ tests. Tests ran on a Debian machine running inside a virtual machine. The purpose of this test was to show relative performance between the different serialization formats, which should not be affected by running inside a virtual machine.
As to be representative of how the serialization data might be used, all write tests were passed the same input data, either a vector (for the C++ tests) or a List (for the Python tests) of Person objects. Each Person contains an ID (an integer starting from 0), a name (random string of 5 ASCII chars), an address (random string of 20 ASCII chars) and an age (float). Each test was required to serialize the data to the required format (using the libraries mentioned above) and then write the serialized data to disk. All read tests performed the opposite task, reading a data file, deserializing and creating a vector/List of Person objects.
3 iterations of each test were performed, and the smallest run time of the three was selected as the most representative. Larger runtimes are typically the result of the OS performing extraneous tasks which should not be included in these runtimes.
| Format | C++ Deserialization (s) | C++ Serialization (s) | Python Deserialization (s) | Python Serialization (s) |
|---|---|---|---|---|
| csv | 0.030 | 0.022 | 0.027 | 0.034 |
| json | 0.16 | 0.13 | 0.023 | 0.16 |
| protobuf | 0.015 | 0.025 | 0.26 | 0.38 |
| toml | 0.23 | 0.22 | 1.08 | 0.23 |
| xml | 0.12 | 0.16 | 0.063 | 0.25 |
| yaml | 0.48 | 0.55 | 6.84 | 3.84 |
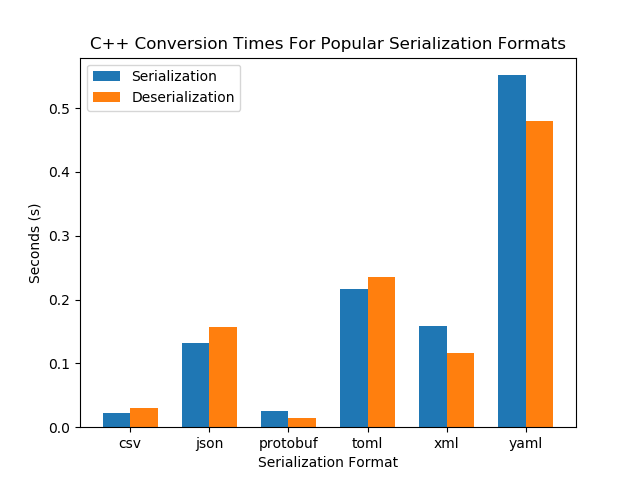
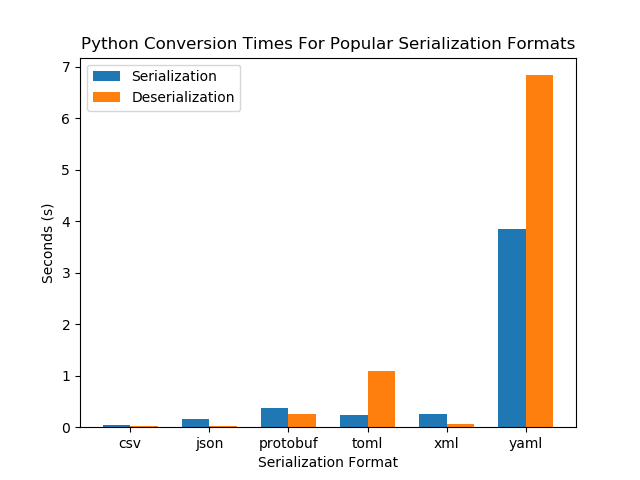
It is also interesting to see how the serializations respond to a change in the data size. If the size of the data doubles, does it take twice as long to read/write (linear response), or does it behave differently (e.g. quadratic, , …)? This is called the complexity of the serialization algorithm. To test this, I increased the people array from 10,000 to 100,000 (increased by a factor of 10). This was the result…
| Format | C++ Deserialization (s) | C++ Serialization (s) | Python Deserialization (s) | Python Serialization (s) |
|---|---|---|---|---|
| csv | 0.26 | 0.18 | 0.22 | 0.38 |
| json | 1.53 | 1.50 | 0.20 | 1.59 |
| protobuf | 0.13 | 0.24 | 2.62 | 3.61 |
| toml | 2.23 | 2.19 | 9.86 | 2.08 |
| xml | 0.85 | 1.74 | 0.78 | 2.58 |
| yaml | 4.96 | 5.70 | 69.67 | 36.87 |
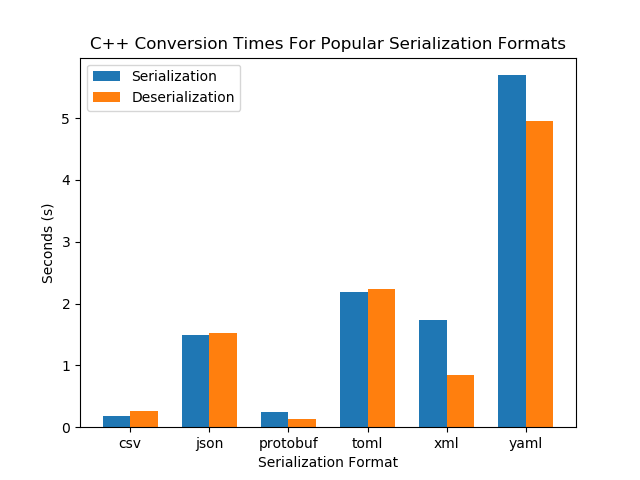
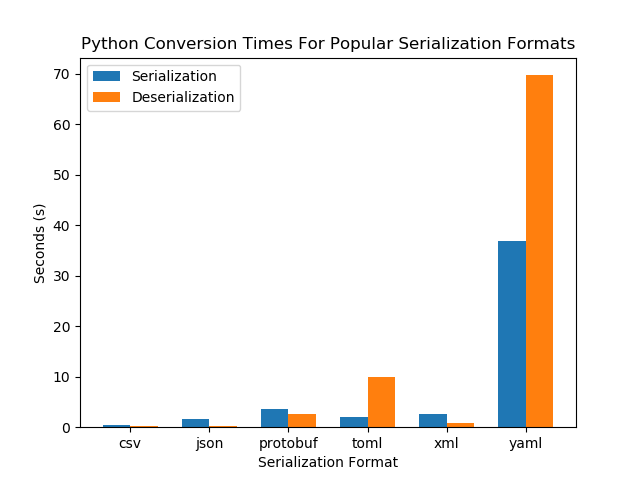
The code that performed these tests can be found at https://github.com/gbmhunter/BlogAssets/tree/master/Programming/serialization-formats.
File Size Comparison
When serializing large amounts of data, another important aspect is the verbosity of the format. To compare the verbosity of the different formats, we can pass each format the same data, dump the data to disk, and compare the file sizes.
| Format | File Size (MiB, 10k records) | File Size (MiB, 100k records) |
|---|---|---|
| csv | 0.50 | 5.0 |
| json | 0.89 | 8.9 |
| protobuf | 0.38 | 3.8 |
| toml | 0.88 | 8.8 |
| xml | 1.11 | 11.1 |
| yaml | 0.78 | 7.8 |
As expected, the file sizes grow linearly with the number of records stored (10x amount of data = 10x the file size).
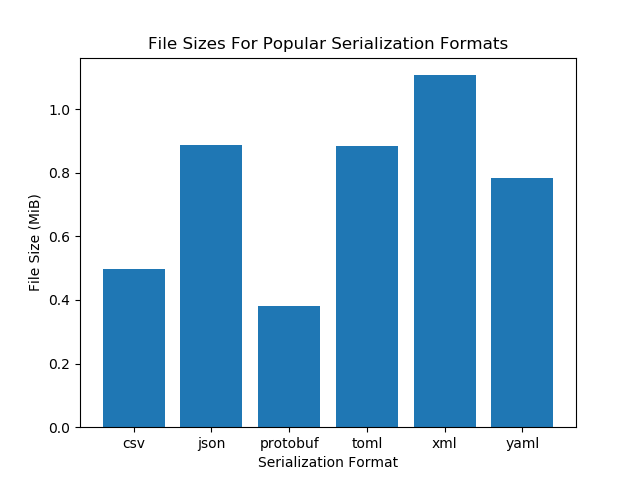
Being the only binary, non-human readable format that was compared, it is no surprise that protobuf is the most concise format. Closely behind protobuf was CSV. Because CSV does not support irregular, non-flat data structures, it only requires a value delimiter (e.g. ,) and end of line character (e.g. \n).
Other Formats That Weren’t Considered
- Apache Avro: A binary-based data serialization standard by Apache.
- BSON. A binary format popularized by MongoDB that is based on JSON.
- Cap’n Proto. A “cerealization protocol”…:-D. See their website for more details.
- JSON5. A superset of JSON which allows for multi-line strings, comments, single-quote string delimiters, and more.
- HOCON: A serialization format that seems popular in Java.
- MessagePack. This looks similar to protobuf (uses binary encoding). Has libraries for a wide variety of languages.
- SDLang: A XML-like serialization format (but without the angled brackets) with libraries available in .NET, Java, PHP, Ruby and other languages.
- XDR (RFC4506): The External Data Representation (XDR) is a well-used but specialized (i.e. the average developer does not use this protocol on a day-to-day basis) serialization protocol.