Consistent Overhead Byte Stuffing (COBS)

Consistent overhead byte stuffing (COBS) is a byte-stuffing algorithm for framing serial data which provides a consistent, guaranteed maximum overhead per quanta of data (i.e. fixed amount of overhead per n bytes of data). Framing allows the use of a special byte value which can be used to mark the end of the packet, so that a decoder on the other end of a serial communication bus/network can reliably split up one packet from the next and decode the data. It is commonly paired with one of the many serialization formats (e.g. Protocol Buffers, MessagePack, CBOR, plain C struct) used in embedded systems to send data over a serial link.
The Encoding/Decoding Process
COBS encoding produces an output stream of bytes in the range [1, 255] (i.e. containing no 0x00) so that 0x00 (or any other one byte) can be used to unambiguously mark the end of the packet. The encoding process is best explained with a diagram as below:
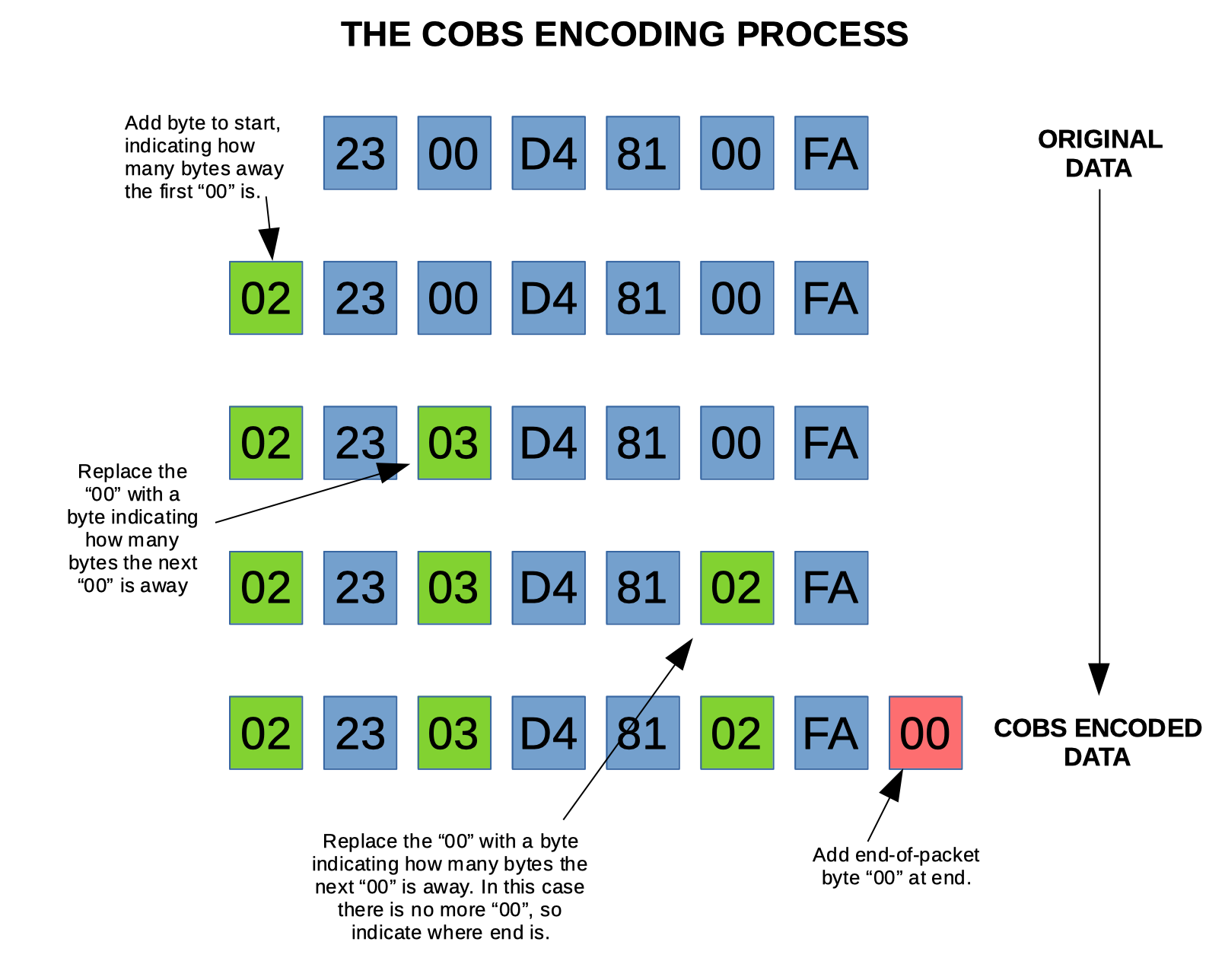
Dealing With 255 Bytes
The one problem with using a single byte to store the distance to the next 0x00 arises when the next 0x00 is more than 255 bytes away. It should now be obvious why, as a single byte cannot store a number higher than 255 (0xFF). So a special thing happens when this occurs --- if you encounter a “pointer” byte with 0xFF, it doesn’t mean the next 0x00 is 255 bytes away, it means that there were no 0x00’s in the next 254 bytes, and that the 255th byte will contain the next pointer.
Because we have reserved the pointer value 0xFF, we can only use the pointer values 0x01 through to 0xFE to indicate where a real 0x00 is next in the data.
A follow-on effect of this rule is that for a large amount of data containing no 0x00’s, a 0xFF pointer byte will be added after every 254 bytes. This is where the Consistent Overhead part of the COBS acronym comes from. Many other packetization/framing algorithms suffer from the fact that the payload can increase significantly if the data contains the specific problematic values (e.g. many algorithms produce a payload which is double the size of the original data!).
Some Examples
One of the quickest ways to understand how COBS works is to look at some simple examples of raw and encoded data. The following table shows basic examples which demonstrate the encoding process and highlight the edge-cases. All data is byte-wise in hexadecimal.
| Raw Data (hex) | Encoded Data (hex) |
|---|---|
| 00 | 01 01 00 |
| 01 | 02 01 00 |
| 02 | 02 02 00 |
| 03 | 02 03 00 |
| 00 00 | 01 01 01 00 |
| 00 01 | 01 02 01 00 |
| 01 02 03 … FD FE FF | FF 01 02 03 … FD FE 02 FF 00 |
Comparing Overhead With Traditional (Escape-Based) Byte Stuffing
COBS is itself a form of byte stuffing (the “BS” in its name) --- the general technique of transforming a payload so a reserved delimiter value can never appear inside it. A popular alternative is escape-based byte stuffing, as used by SLIP (Serial Line Internet Protocol) --- the same scheme also underlies PPP and KISS.1 SLIP reserves an END byte (0xC0) to mark the end of a frame, and an ESC byte (0xDB) to escape any END or ESC that appears in the payload. Each occurrence of one of these two byte values in the data is replaced by a two-byte escape sequence.
The trade-off between the two schemes is starkest in their worst and average cases. Let the payload be bytes, with each byte value in [0, 255] equally likely. So a given byte is zero with probability and non-zero with probability .
Worst Case
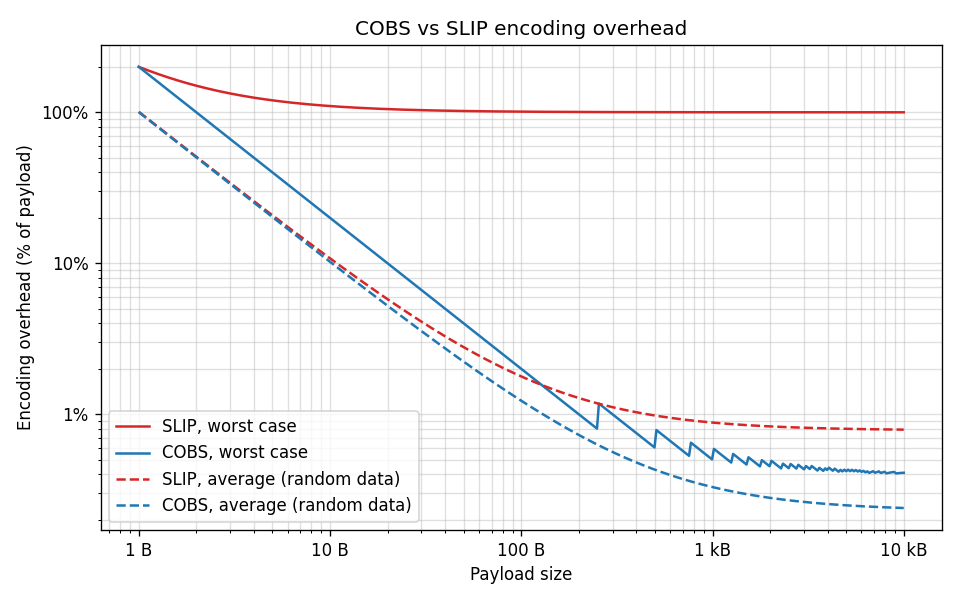
SLIP: if every payload byte happens to be 0xC0 or 0xDB, every byte expands to two and the frame doubles in size (100% overhead). This unbounded blow-up is exactly the problem COBS was designed to solve.
COBS: the overhead is one byte per block of up to 254 non-zero bytes, i.e. bytes.2 That is at most about 0.39% (1 byte per 254), which is much better than SLIP-based byte stuffing.
Average Case (Uniformly Random Data)
SLIP: two of the 256 byte values must be escaped, each adding one byte, so the expected overhead per payload byte is
COBS: extra bytes appear only when a run of 254 non-zero bytes occurs. The probability of such a run is , and the expected overhead per payload byte works out to
The derivation: each COBS block consumes data bytes, where is the distance to the next zero, and contributes one byte of overhead only when it is a forced 254-byte split (which happens with probability ).
Putting Numbers On It
Both schemes also need a fixed delimiter to mark the frame boundary: COBS appends a single 0x00, and SLIP sends an END byte at the end of the frame (many implementations also send a second END at the start to flush line noise).1 This is a constant cost that does not scale with (so the per-byte rates above ignore it) but it is included in the totals below.
For a 1500-byte payload (a typical Ethernet MTU, the example used in the original COBS paper),2 counting one delimiter byte per frame:
| Scheme | Worst-case overhead | Average overhead (random data) |
|---|---|---|
| SLIP byte stuffing | 1501 bytes (~100%) | ~13 bytes (0.85%) |
| COBS | 7 bytes (0.47%) | ~4.4 bytes (0.30%) |
COBS wins on both counts, but the decisive difference is the worst case: SLIP can double your data, whereas COBS guarantees the overhead stays under half a percent no matter what the payload contains.
The graph below plots the overhead (as a percentage of the payload) against payload size for both schemes, in both the worst and average cases. Note the log-log axes! SLIP’s worst case trends to 100% regardless of size, while COBS’s worst case falls away to its ~0.39% asymptote (the sawtooth is the integer stepping of the stuffing bytes).
Why Does This Matter?
In embedded systems, microcontrollers are usually quite memory constrained. Typically, when implementing a communications protocol, you have to allocate a buffer for the maximum size of the payload you expect to receive. You will normally be thinking about payload size in terms of unencoded data you want to send (i.e. the size of the message structs defining your data, or the size of protobuf messages, etc.). But the buffer has to hold the encoded data. If your framing scheme can double the size of the payload, your buffer must be twice as big also (to guarantee it can hold the worst-case scenario). For a 1 kB max. payload size this is a 2 kB buffer. These buffers can quickly consume the limited RAM available on a microcontroller.
COBS provides a solution to this issue by guaranteeing a maximum overhead of 1 byte per 254 bytes of data. So for a 1 kB max. payload size, the buffer only needs to be bytes (payload, plus worst-case stuffing, plus the delimiter), which is a huge saving in RAM.
COBS Encoder/Decoder
The interactive tool below encodes raw bytes into a COBS frame (appending the 0x00 delimiter), or decodes a COBS frame back to the original data. Enter the bytes as hex, separators like spaces, commas, colons and 0x prefixes are all accepted.
Also, use the “Buffer size” mode to calculate the maximum encoded size for a given max. payload size, which is useful for allocating buffers in embedded systems.
Raw data (hex)
COBS frame (hex)
Source Code
I wrote C++ functions which can perform COBS encoding and decoding as part of an open source serial communications protocol, they can be found in CobsTranscoder.cpp in the SerialFiller repo.
History and Usage
In 1997/1999 there was an attempt to standardize COBS as an alternative to HDLC framing in PPP (Point-to-Point Protocol), specifically because HDLC’s worst-case overhead can double the frame size. It was submitted as an IETF internet draft, but never progressed to an RFC and therefore was never standardized for PPP.3
In Rust the postcard and postcard-rpc libraries use COBS for framing. postcard is a embedded serialization framework and remote procedure call (RPC) system.
Espressif’s ESPP library for ESP32 comes with a COBS module.4 Kirale (a Thread/802.15.4 vendor) uses COBS for their serial host interface.5 Cyphal, a communication protocol used in aerospace, drones and robotics uses COBS framing for its serial transport (UART, RS-232/422, USB CDC ACM, and TCP).6
Footnotes
-
J. Romkey (1988, Jun). RFC 1055: A Nonstandard for Transmission of IP Datagrams over Serial Lines (SLIP) [RFC]. IETF. Retrieved 2026-06-26, from https://www.rfc-editor.org/rfc/rfc1055. ↩ ↩2
-
Stuart Cheshire & Mary Baker (1999, Apr). Consistent Overhead Byte Stuffing [paper]. IEEE/ACM Transactions on Networking. Retrieved 2026-06-26, from http://www.stuartcheshire.org/papers/COBSforToN.pdf. ↩ ↩2
-
James D. Carlson, Stuart Cheshire & Mary Baker (1997, Nov). PPP Consistent Overhead Byte Stuffing (COBS) [specification]. IETF. Retrieved 2026-06-27, from https://datatracker.ietf.org/doc/html/draft-ietf-pppext-cobs-00. ↩
-
Espressif Systems. COBS (Consistent Overhead Byte Stuffing) Component for ESP-IDF [product page]. Retrieved 2026-06-27, from https://components.espressif.com/components/espp/cobs/versions/1.1.3/readme. ↩
-
KiraleTech. KiraleTech/KiTools [GitHub repository]. GitHub. Retrieved 2026-06-27, from https://github.com/KiraleTech/KiTools. ↩
-
OpenCyphal Development Team (2025, May 16). Cyphal Specification v1.0 [specification]. Retrieved 2026-06-27, from https://specification.opencyphal.org/Cyphal_Specification.pdf. ↩