Understanding Logistic Regression

Logistic regression (or logit regression) is a very common and popular algorithm that is used in machine learning. It is used for making binary categorical predictions, such as “is it going to rain today?” or more precisely, it can be used to give a percentage chance of it raining today. Logistic regression can also be extended to make many-option categorical predictions, such as “is it more likely to be sunny, overcast, or rainy today?”.
Probability and Odds
Before learning about logistic regression, it is wise to understand the terms probability and odds.
We’ll start with a real simple equation. The probability of a binary event occurring is:
The probability of a binary event not occurring must then be:
The odds is defined as the ratio of success to the ratio of failure.
It should be clear from the above equation that if can vary in the range then can vary in the range . The higher the odds, the higher the chance of success. This should sound very familiar to gamblers, who use this term frequently.
Why Use The Logarithmic Function?
The reason we introduce the function into the equation begins to make sense once you understand basic linear regression, which can be used to predict the probability of continuous target variables. The basic equation defining linear regression involving just one predictor and the outcome is:
where:
are the coefficients
is the predictor
is the outcome
The problem with using linear regression for making binary categorical predictions (i.e. true/false) is that can vary from to . We really want to range from to . When varying between and , this tells us the probability of the target being true or false. For example, if this would say there is a 70% chance of the target being true, and conversely a 30% chance of the target being false.
To make things less confusing, we will replace which is used to represent a continuous target variable with (for probability), which is used to represent the probability:
Notice a problem? This limits of the LHS and RHS of the equation don’t match up! This is where we begin to understand why the log function is introduced. We will try and modify the RHS such that it has the same range as the LHS ( to ). What if we replace the probability on the LHS with the odds :
where:
are the odds
We are getting closer! Now the RHS varies from to rather than from just to . So how do we modify a number which ranges from to to range from to ? One way is to use the ln() function! (to recap some mathematics, the ln of values between 0 and 1 map from and , and the ln of values from to map to to .)
The ranges on both sides of the equation now match! The base of the logarithm does not actually matter. We choose to use the natural logarithm () but you could use any other base such as base 10 (typically written as or just ).
Now we can see why it’s called logistic regression, and why it is useful.
However, the equation is usually re-arranged with on the LHS.
As you can see from above, is now a form of a sigmoid function.
What Does The Logistic Function Look Like?
So we have the basic logistic function equation:
where:
and are constants
What happens as we change ?
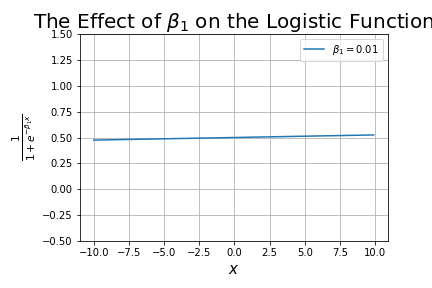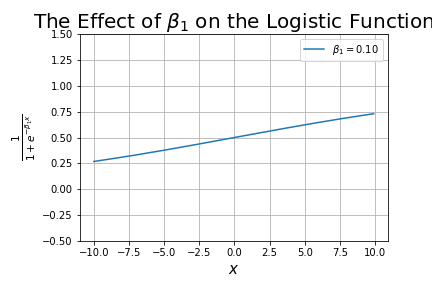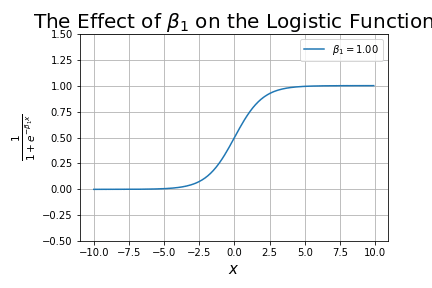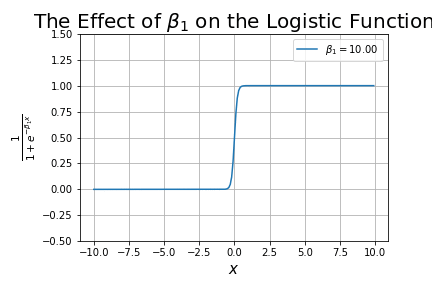
It changes the shape of the curve, starting-off looking like a linear line, and progressively getting closer to looking like a step function. This term is analogous to the slope in linear regression.
What happens as we change ?
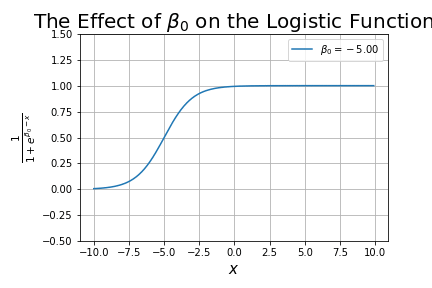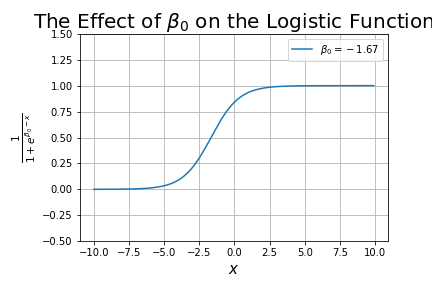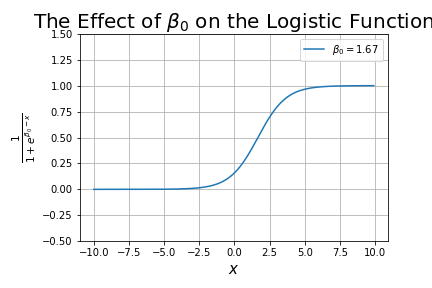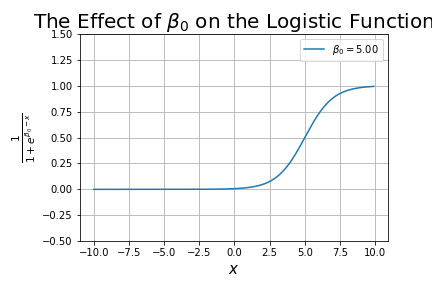
This is analogous to the y-intercept in linear regression, except that shifts the curve along the x-axis.
Worked Example
We can use logistic regression to perform basic “machine learning” tasks. We will use the famous Iris dataset, and write the code in Python, leveraging sklearn’s logistic regression training class and various reporting tools. The Iris dataset is popular enough that it’s bundled with a number of Python libraries, including seaborn (which is where we will grab it from):
import seaborn as snsfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, classification_reportfrom sklearn.model_selection import train_test_splitdata = sns.load_dataset('iris')print(data.shape[0])# 150data.head()
Split the data into the features x and the target y:
x = data.iloc[:, 0:-1] # All columns except "species"y = data.iloc[:, -1] # The "species" columnNow split the data into training and test data:
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)Let’s train the model:
model = LogisticRegression()model.fit(x_train, y_train) # Training the modelMake predictions:
predictions = model.predict(x_test)print(predictions)
Print a “classification report”:
print(classification_report(y_test, predictions))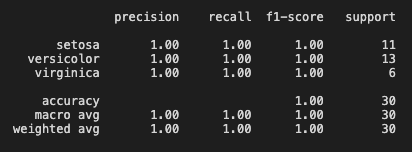
For someone new to categorization, these terms in the classification report can be confusing. This is what they mean1:
-
The precision is how well the classifier is at labelling an instance positive when it was actually positive. It can be thought of as: “For all instances labelled positive, what percentage of them are actually correct?
-
The recall is the ability for a classifier to find all true positives. It can be though of as: “For all instances that where actually positive, what percentage were labelled correctly?”
-
The f1-score is the harmonic mean of the precision and recall. Personally I find this the most difficult metric to understand intuitively. It is a score which incorporates both the precision and recall, and varies between 0 and 1.
-
The support is the number of actual occurrences of a class in a specific dataset.
And let’s print the accuracy score:
print(accuracy_score(y_test, predictions))# 0.9666666666666667