Windowed Moving Average Filters

Windowed moving average filters are a family of filters which have a finite impulse response (FIR). They all use a finite-length window of data points to calculate the averaged output. The easiest moving average filter to understand is the Simple Moving Average (SMA) filter (also called a box-car filter), which uses a window in where all the inputs values are weighted equally (coefficients are equal). Other moving average filters include the Windowed Exponential Moving Average (EMA) filter, with exponentially-weighted coefficients.
Terminology
First off, some terminology.
Window Size (N)
- Symbol:
The window size is number of data points used in a moving average filter. is another letter commonly used to represent the same thing.
Normalized Frequency (F)
- Symbol:
The normalised frequency, with units . This describes an frequency component in a filter relative to the sampling frequency (e.g. a normalized frequency of 0.1 means there are 10 samples per cycle. The signal is at Nyquist when . This is a frequency in the discrete time-domain. Do not confuse with which is a frequency in the continuous time-domain.
To convert from a standard frequency to a normalized frequency , use the equation:
where:
is the normalized frequency, in
is the standard frequency, in
is the sample rate, in
The normalized frequency can also be expressed in radians, and if so uses the symbol . This has the units .
Frequency (f)
- Symbol:
A frequency of a waveform in the continuous time-domain. Do not confuse with , which is a frequency in the discrete time-domain.
Sampling Frequency ()
The sample frequency of a waveform, measured in the continuous time-domain. This parameter is used when you want to convert a input waveform frequency from a continuous time-domain frequency to a normalised discrete time-domain frequency (see more here).
Simple Moving Average Filter
The simple moving average (SMA) filter (a.k.a rolling average filter) is one of the most commonly used digital filters (or averaging device), due to it’s simplicity and ease of use. Although SMA filters are simple, they are first equal (there are other filters that perform as good as, but not better) at reducing random noise whilst retaining a sharp step response. However, they are the worst filter for frequency domain signals, they have a very poor ability to separate one band of frequencies from another1.
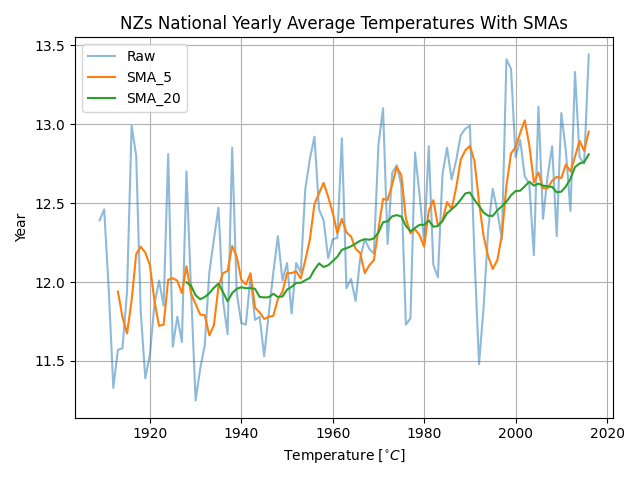
The following plot shows the effect of a SMA filter. The data used is New Zealand’s national average temperature (data from https://data.mfe.govt.nz/table/89453-new-zealands-national-temperature-19092016/):
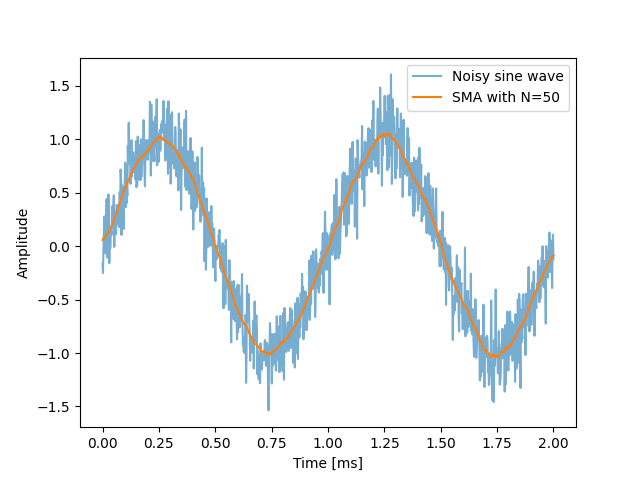
The below plot shows a noisy 1kHz sine wave (with random, normally distributed noise) and then the application of a SMA filter (symmetric, window size = 50) which does a commendable job at recovering the original signal:
There are two common types of simple moving average filters:
- Left-handed SMA
- Symmetric SMA
A left-handed simple moving average filter can be represented by:
where:
= the input signal
= the output signal
= the number of points in the average (the width of the window)
For example, with a windows size of , the moving average at point 9 would be sum of the last 5 inputs thru to divided by 5:
Left-handed filters of this type can be calculated in real-time ( can be found as soon as is known).
The window can also be centered around the output signal (a symmetric moving average filter), with the following adjustment of the limits:
For example, using our again:
Symmetric simple moving averages require to be odd, so that there is an equal number of points either side. The advantage of a symmetric filter is that the output is not delayed (phase shifted) relative to the input signal, as it is with the left-handed filter. One disadvantage of a symmetric filter is that you have to know data points that occur after the point in interest, and therefore it is not real time (i.e. non-casual). Most SMA filters used on stock market data use a left-handed filter so that it is real-time.
When treating a simple moving average filter as a FIR, the coefficients are all equal. The order of the filter is 1 less than the value you divide each value by. The coefficients are given by the following equation:
A simple moving average filter can also be seen as a convolution between the input signal and a rectangular pulse whose area is 1.
Frequency Response
The frequency response for a simple moving average filter is given by:
where:
is the frequency response
the normalised frequency, in
= the number of points in the average (the width of the window)
Note that the sine function uses radians, not degrees. You may also see this shown in angular frequency units (), in which case . To convert from a standard frequency to a normalized frequency , use the equation:
where:
is the normalized frequency, in
is the standard frequency, in
is the sample rate, in
To avoid division by zero, use . The magnitude follows the shape of a function.
The frequency response can also be written as2:
Lets design a SMA filter with a sampling rate of and a window size of . This gives the following magnitude response:
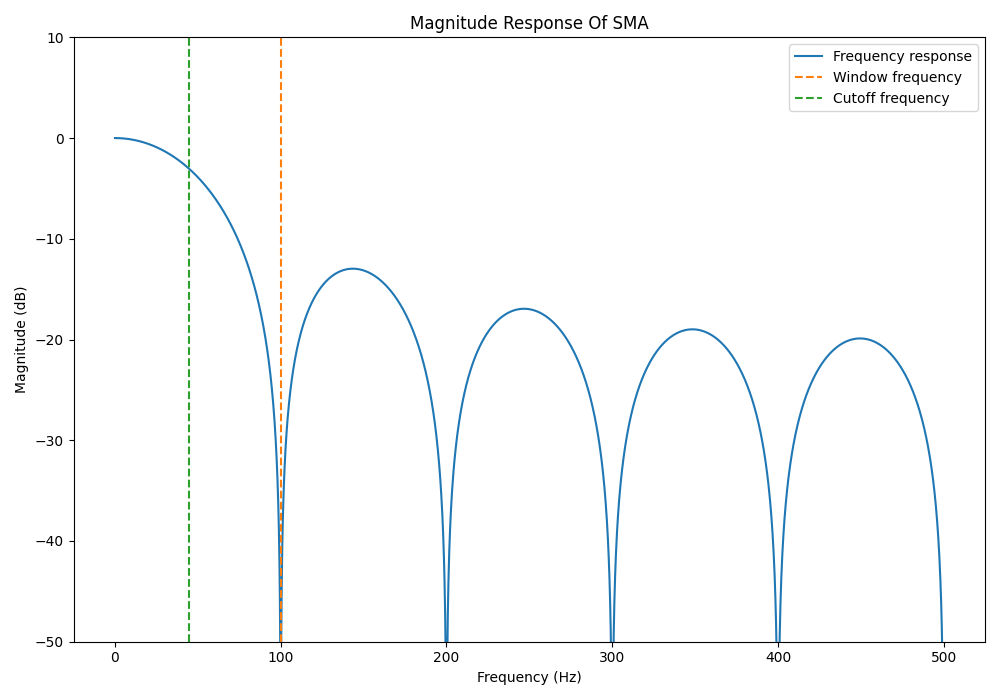
As expected, this shows us that at DC, the signal is not attenuated at all. As the frequency increases, the filter then begins to block more and more, until it lets through absolutely no signal at . This can be intuitively understood, because with a sampling frequency and a window size of , a single cycle of a signal would fit perfectly into the window. Since you take the average of all the values in the window, this top half of the signal would cancel out perfectly with the bottom half, giving no output. But then, as the frequency further increases, the filter begins to let through some of the signal, as shown by the side lobes. The next point of infinite attenuation is at , which is when 2 cycles of the signal would fit perfectly into the window. This cycle occurs all the way up to Nyquist at .
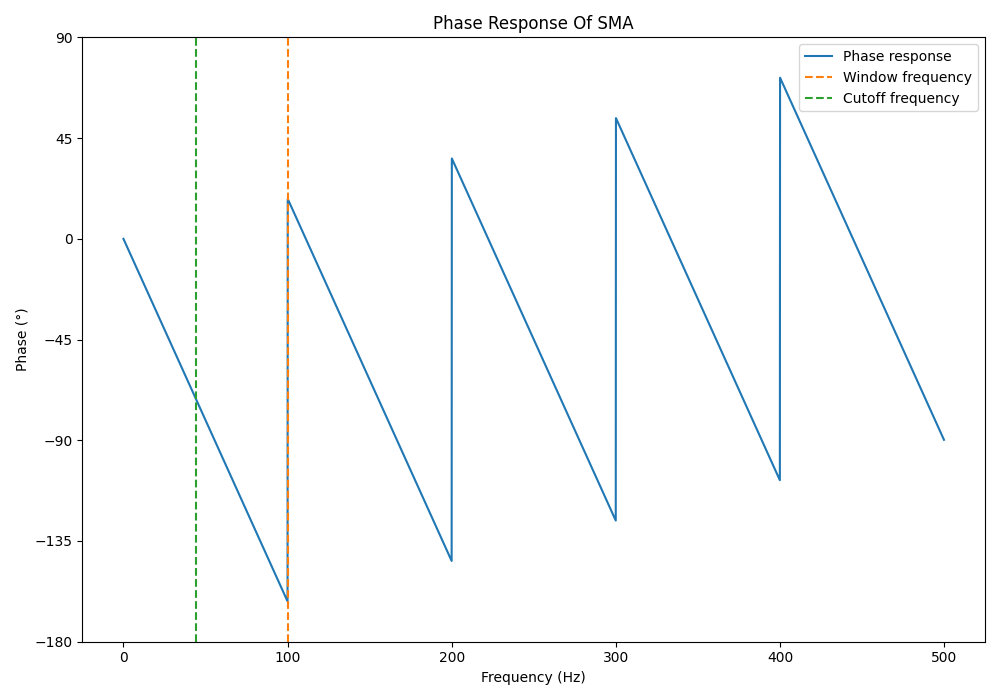
The phase response of the same filter is shown below:
For interest, let’s have a look at how increasing the window size effects the frequency response:
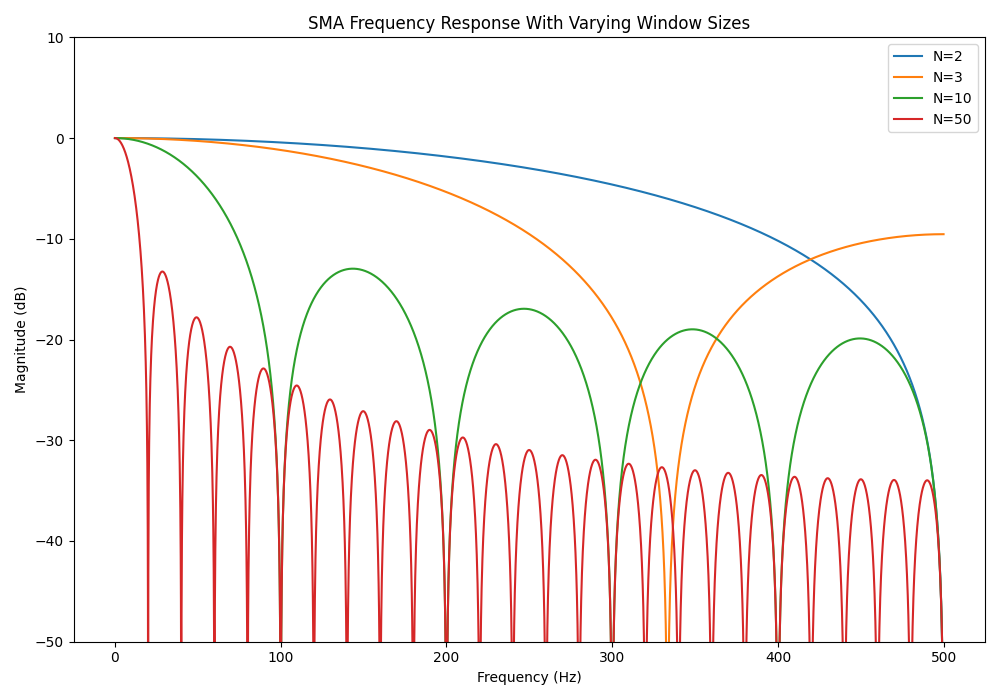
As expected, increasing the window size decreases the cut-off frequency and also improves the roll-off. However, for a left-handed (casual) SMA filter, it also significantly increases the phase shift (or time delay!), so normally a trade-off has to be made.
Cutoff Frequency
When designing a SMA filter, you typically want to set the window size based on the frequencies you want to pass through and those you want reject. The easiest figure of merit for this is the cutoff frequency (or ), which we’ll define here as the power point ( point). This is the frequency at which the power of the signal is reduced by half.
We can find the equation for the cutoff frequency from above.
Unfortunately, no general closed form solution for the cutoff frequency exists (i.e. there is no way to re-arrange this equation to solve for ). However, these are two ways to get around this problem.
- Solve the equation numerically, e.g. use the Newton-Raphson method.
- Use an equation which approximates the answer (easier method, recommended approach unless you really need the accuracy!)
Numerically
The Newton-Raphson method can be used to solve the above equation. Below is a code example in Python which includes the function get_sma_cutoff() that can calculate the cutoff frequency given the window size to a high degree of accuracy3:
import numpy as npimport scipy.signal
def get_sma_cutoff(N, **kwargs): """ Function for calculating the cut-off frequency of a simple moving average filter. Uses the Newton-Raphson method to converge to the correct solution.
This function was initially written by Pieter P. (https://tttapa.github.io/Pages/Mathematics/Systems-and-Control-Theory/ Digital-filters/Simple%20Moving%20Average/Simple-Moving-Average.html).
Args: N: Window size, in number of samples.
Returns: The angular cut-off frequency, in rad/s. """ func = lambda w: np.sin(N*w/2) - N/np.sqrt(2) * np.sin(w/2) # |H(e^jω)| = √2/2 deriv = lambda w: np.cos(N*w/2) * N/2 - N/np.sqrt(2) * np.cos(w/2) / 2 # dfunc/dx omega_0 = np.pi/N # Starting condition: halfway the first period of sin(Nω/2) return scipy.optimize.newton(func, omega_0, deriv, **kwargs)Approximate Equation
An approximate equation can be found relating the window size to the cutoff frequency which is accurate to 0.5% for 4:
where:
is the window size, expressed as a number of samples
is the normalized cutoff frequency
Remember that can be calculated with:
where:
is the cutoff frequency, in Hertz
is the sample frequency, in Hertz
Recursive SMA Implementation
The computation power required to calculate the output at each step in a SMA filter can be significantly reduced with a simple trick. For example, consider a basic left-handed SMA with a window size of 5:
Instead of calculating each output as above, we can instead save the last output value we calculated, add the new input data point to it, and subtract the oldest data point from the window:
This is called a recursive algorithm1, because the output of one step is used in the calculation of future steps. It’s main benefit is the tremendous speed increase in computing each step, especially when the window size is large. Whilst this dependence on previous output ( depends on ) makes it look like an IIR filter, this recursion trick does not change the SMAs behaviour, and it still an FIR filter (once the input flies “past” the end of the window, it has no bearing on the output).
One thing to watch out for is accumulated error if using floating point numbers. Because you are now calculating the next output value from the previous output calculation (rather than fresh input data, as you would for the non-recursive algorithm), floating point precision errors will accumulate slowly in the output.
To show this, the following graph plots the accumulated error when using 32-bit floating point numbers. 10 million random 32-bit floats in the range of (our input data) was pushed through a left-handed SMA with a window size of 10 (the window size should not really matter). On every 100th input, the output value as computed by the recursive algorithm was compared with the output computed by the non-recursive algorithm. The difference between these two values is the accumulated error.
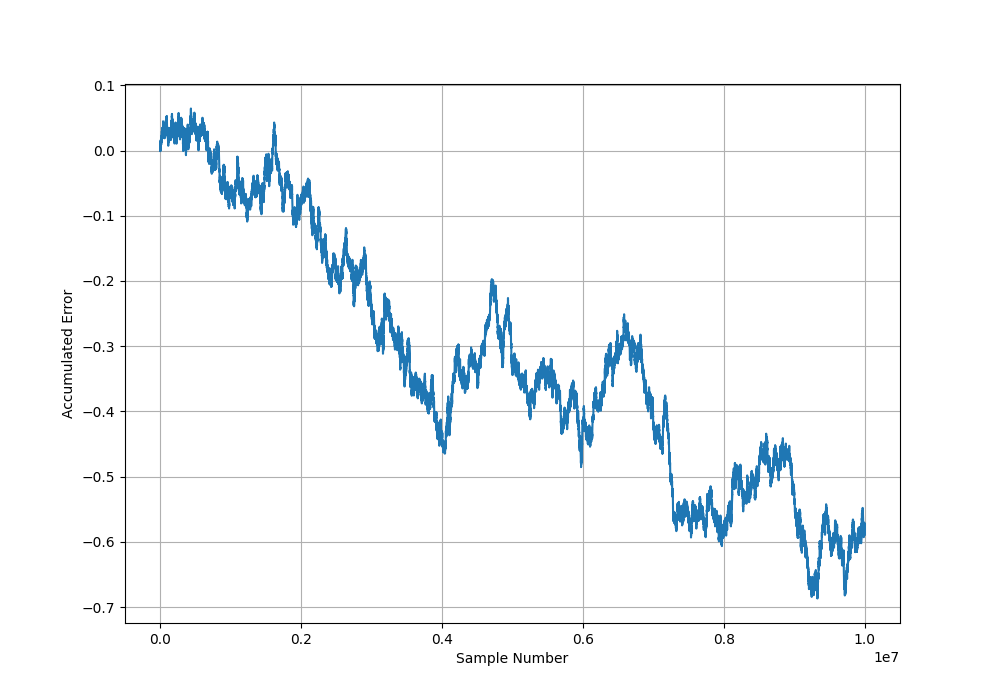
By the time the 10 million inputs have passed through the filter, the answer is wrong by about 0.6! This may or may not be a bad thing depending on your application. I guess (no proof!) that the average error will grow proportional to the square root of the number of samples pushed through the filter, similar to a random walk (drunkards walk).
Integer based data does not have this accumulation error problem with the recursive SMA. If you did need to use floats, and you don’t have the CPU brute to use the non-recursive method, one solution may be to periodically clear the previous output value and recompute the output using the non-recursive equation. This will reset your error back to 0, preventing it from growing without bound.
Similarity To Convolution
A SMA filter is identical to the convolution (a mathematical concept) of the input signal with the window waveform (kernel). Typically you would set the height of each point in the window to , so that the area under the window curve is 1 (and the SMA has no gain). For example, a 5-point window waveform would have the values:
Multiple Pass Moving Average Filters
A multiple pass simple moving average filter is a SMA filter which has been applied multiple times to the same signal. Two passes through a simple moving average filter produces the same effect as a triangular moving average filter (convolution of a square wave with a square wave is a triangle wave). After four or more passes, it is equivalent to a Gaussian filter1.
Code Examples
The following code shows how to create a left-handed SMA filter in Python. Note that this example is to show the logic behind the algorithm. For fast and easy SMA use in Python I would recommend using Numpy’s np.convolve() or Panda’s pd.Series.rolling().
def sma_example_code(): """ Example code of recursive left-handed SMA. """
inputs = [1, 6, 3, 4, 2]
window_length = 3 moving_average = 0 window = [0]*window_length curr_pos = 0
for idx, input in enumerate(inputs): # Use recursive SMA algorithm moving_average = moving_average + (1/window_length)*(input - window[curr_pos])
# Save new input into window at correct position (overwrite oldest) window[curr_pos] = input
curr_pos += 1 if curr_pos >= len(window): curr_pos = 0
if idx < window_length - 1: # SMA not yet valid print(f'y[{idx}] = NAN') else: print(f'y[{idx}] = {moving_average:.2f}')The output is:
y[0] = NANy[1] = NANy[2] = 3.33y[3] = 4.33y[4] = 3.00Fast Start-up
Like all filters, the simple moving average filter introduces lag to the signal. You can use fast start-up logic to reduce the lag on start-up (and reset, if applicable). This is done by keeping track of how many data points have been passed through the filter, and if less have been passed through than the width of the window (i.e. some window elements are still at their initialised value, normally 0), you ignore them when calculating the average.
This is conceptually the same as having a variable-width window which increases from 1 to the maximum value, , as the first values are passed through the filter. The window width then stays at width for evermore (or until the filter is reset/program restarts).
If you also know a what times the signal will jump significantly, you can reset the filter at these points to remove the lag from the output. You could even do this automatically by resetting the filter if the value jumps by some minimum threshold.
Exponential Moving Average (EMA) Filters
Unlike a SMA, most EMA filters is not windowed, and the next value depends on all previous inputs. Thus most EMA filters are a form of infinite impulse response (IIR) filter, whilst a SMA is a finite impulse response (FIR) filter. There are exceptions, and you can indeed build a windowed exponential moving average filter in where the coefficients are weighted exponentially.
A exponentially weighted moving average filter places more weight on recent data by discounting old data in an exponential fashion. It is a low-pass, infinite-impulse response (IIR) filter.
It is identical to the discrete first-order low-pass RC filter.
The difference equation for an exponential moving average filter is:
where:
= the output ( denotes the sample number)
= the input
= is a constant which sets the cutoff frequency (a value between and )
Notice that the calculation does not require the storage of past values of and only the previous value of , which makes this filter memory and computation friendly (especially relevant for microcontrollers). Only one addition, one subtraction, and two multiplication operations are needed.
The constant determines how aggressive the filter is. It can vary between and (inclusive). As , the filter gets more and more aggressive, until at , where the input has no effect on the output (if the filter started like this, then the output would stay at ). As , the filter lets more of the raw input through at less filtered data, until at , where the filter is not “filtering” at all (pass-through from input to output).
The following code implements a IIR EMA filter in C++, suitable for microcontrollers and other embedded devices5. Fixed-point numbers are used instead of floats to speed up computation. K is the number of fractional bits used in the fixed-point representation.
template <uint8_t K, class uint_t = uint16_t>class EMA { public: /// Update the filter with the given input and return the filtered output. uint_t operator()(uint_t input) { state += input; uint_t output = (state + half) >> K; state -= output; return output; }
static_assert( uint_t(0) < uint_t(-1), // Check that `uint_t` is an unsigned type "The `uint_t` type should be an unsigned integer, otherwise, " "the division using bit shifts is invalid.");
/// Fixed point representation of one half, used for rounding. constexpr static uint_t half = 1 << (K - 1);
private: uint_t state = 0;};Gaussian Window
The 1D Gaussian function is6:
where:
is the standard deviation
A 5-item symmetric Gaussian window with a standard deviation of would give the window coefficients:
[ 0.061, 0.245, 0.388, 0.245, 0.061 ]TODO: Add more info.
A Comparison Of The Popular Window Shapes
Stuck on what window shape to use? If a simple moving average won’t suffice in it’s simplicity, it might then depend on the frequency response you are after. Popular window shapes and their frequency responses are shown below. All the windows shown below are centered windows (and not left-aligned). The window sample weights are normalized to 1.
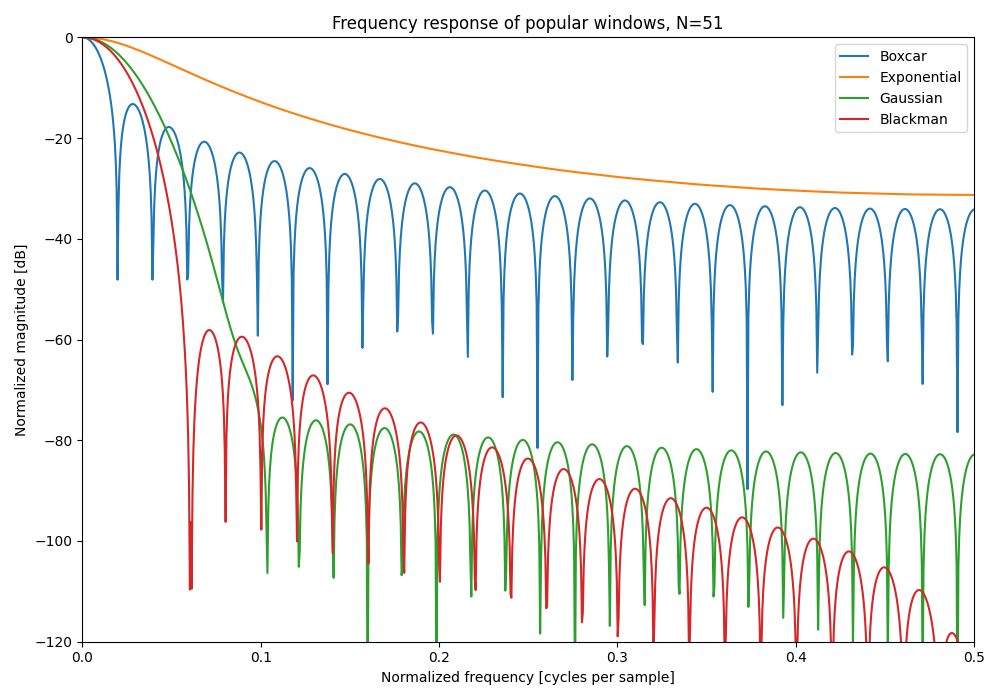
The frequency responses can be found by extending the window waveform with 0’s, and then performing an FFT on the waveform. The resultant frequency domain waveform will be the frequency response of the window. This works because a moving window is mathematically equivalent to a convolution, and convolution in the time domain is multiplication in the frequency domain. Hence your input signal in the frequency domain will be multiplied by FFT of the window.
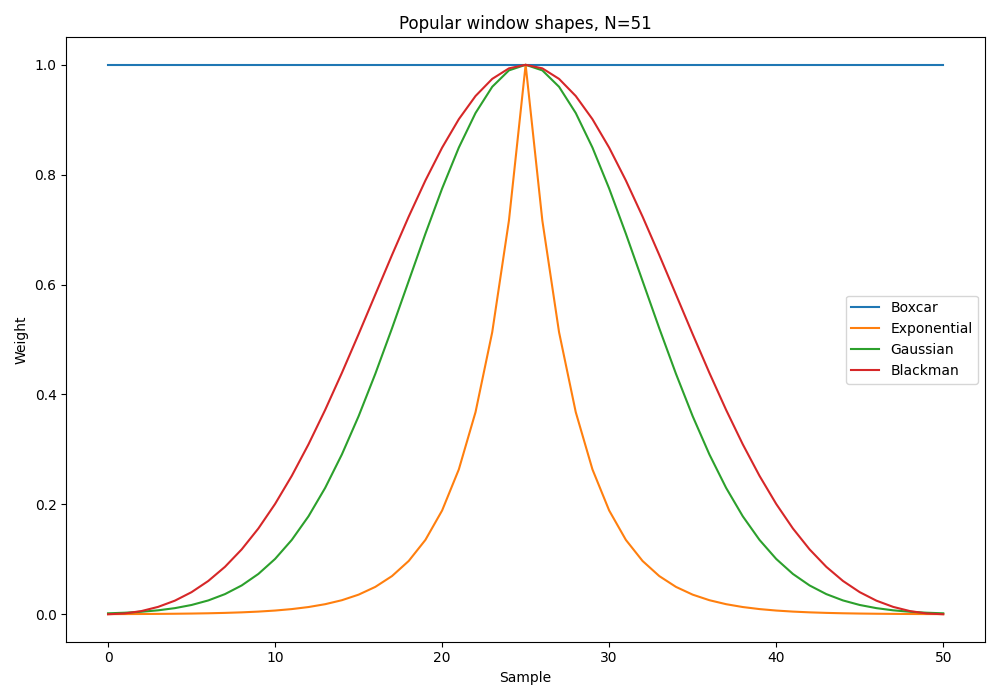
And a comparison of the frequency responses of these windows is shown below:
References
Footnotes
-
https://www.analog.com/media/en/technical-documentation/dsp-book/dsp_book_Ch15.pdf, accessed 2021-05-27. ↩ ↩2 ↩3
-
UC Berkeley. Frequency Response of the Running Average Filter (course notes). Retrieved 2022-05-24, from https://ptolemy.berkeley.edu/eecs20/week12/freqResponseRA.html. ↩
-
https://tttapa.github.io/Pages/Mathematics/Systems-and-Control-Theory/Digital-filters/Simple%20Moving%20Average/Simple-Moving-Average.html, accessed 2021-05-27. ↩
-
https://dsp.stackexchange.com/questions/9966/what-is-the-cut-off-frequency-of-a-moving-average-filter, accessed 2021-05-27. ↩
-
https://tttapa.github.io/Pages/Mathematics/Systems-and-Control-Theory/Digital-filters/Exponential%20Moving%20Average/C++Implementation.html#arduino-example, accessed 2021-05-29. ↩
-
University of Auckland. Gaussian Filtering (lecture slides). Retrieved 2022-05-15 from https://www.cs.auckland.ac.nz/courses/compsci373s1c/PatricesLectures/Gaussian%20Filtering_1up.pdf. ↩