Algorithm Time Complexity

Algorithmic time complexity is a measure of how long it takes for an algorithm to complete when there is a change in size of the input to the algorithm (which is usually the number of elements, . Rather than actually measure the time taken, which varies on the programming language, processor speed, architecture, and a hundred other things, we consider the “time” to be the number of basic operations that the algorithm has to take. This gives us an metric independent on the users computer, that we can use to rate one algorithm against another when solving a problem.
Big-O, Little-o, Theta And Omega
Big-O (pronounced “Big-Oh”), little-o, Theta and Omega are all mathematical methods of describing an algorithms growth as the size of the input increases. We can look at growth in two different ways: the increase in computational cost and the increase in storage (memory).
There are three different mathematical notations used:
- (Big-O) describes the upper bound in complexity
- (little-O) also describes the upper bound in complexity, but is a stronger statement. Big-O is in inclusive upper bound (grows less than or equal to), while little-o is a strict upper bound (grows strictly less than). Big-O is to little-o as is to .
- describes the lower bound in complexity
- describes the exact bound in complexity
(Big-O) is the most commonly used complexity, as we are normally interested in the worst case computational cost/memory usage when choosing/designing an algorithm. Note that you even when using Big-O, you can still talk about average-case and worst-case scenarios, but this is referring to specific inputs and algorithms states which cause the algorithm to perform more poorly than usual.
Normally, we use Big-O notation to describe time complexity (computational cost). Basically, it’s a big with brackets, and inside the bracket you write how the time complexity scales with the input. The input is usually called , and usually represents the “number of things/elements/objects” the algorithm has to deal with.
Big-O notation ignores and constant terms and any constant coefficients (e.g. an algorithm that grows at is still written as . This is because constant terms and constant coefficients do not effect the growth, you can think as Big-O notation as kind of analysis on the “derivative”.
Complexity Algebra
When adding two big-O complexity classes we can move the functions inside the :
Then the larger complexity class becomes dominant and we drop the lower class. For example:
grows faster than , as .
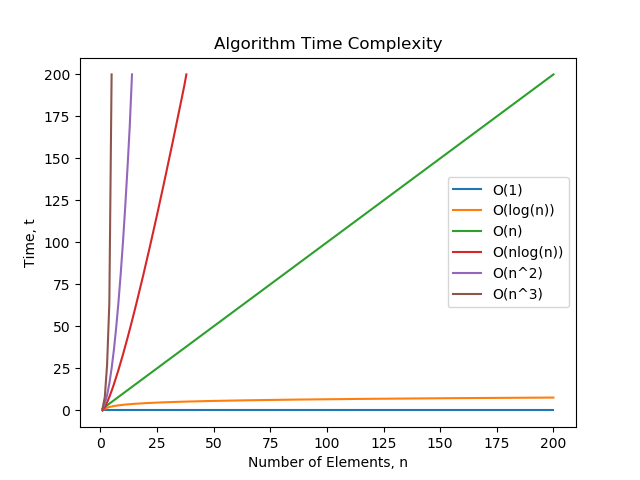
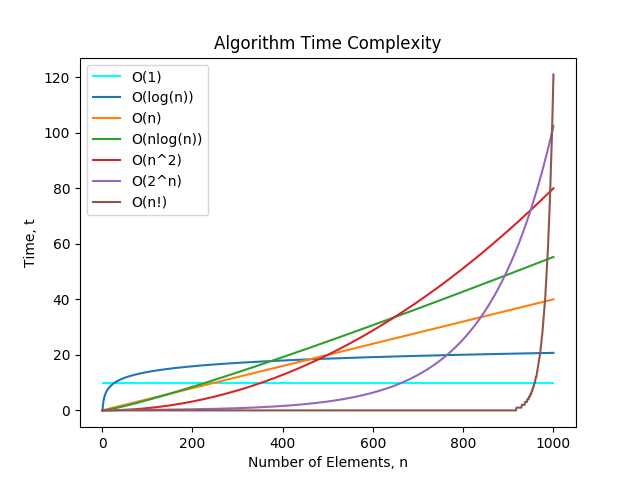
Common Complexity Classes
The following complexity classes are described from best to worst.
Constant Time
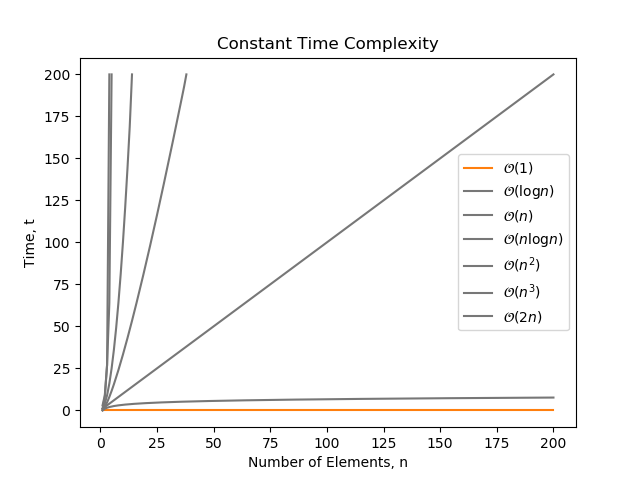
The following algorithm just prints “hello” once, and doesn’t depend on the number of elements (). It will always run in constant time, and therefore is .
print('hello')Note that even though the following algorithm prints out hello three times, it still does not depends on , and runs in constant time. Again, it is still classified as .
print('hello')print('hello')print('hello')complexity is the best algorithm complexity you can achieve. Common software operations that have complexity are:
- Reading a value from an array (e.g. a Python
list, a Carray, or a C++std::vector). To read a value from a from an array, you just read the memory address atbase_address + index * value_size. This takes a constant amount of time, no matter the size of the array. - Reading an element from hash table (e.g. a Python
dictionary). Computing the hash of a key takes a constant amount of time, and then looking up the memory location at that hash is also constant. - Deleting an element from a doubly-linked list.
- Push/pop of a stack.
- Inserting a value at the end of an array (note, this is amortized complexity)
log(n) Time
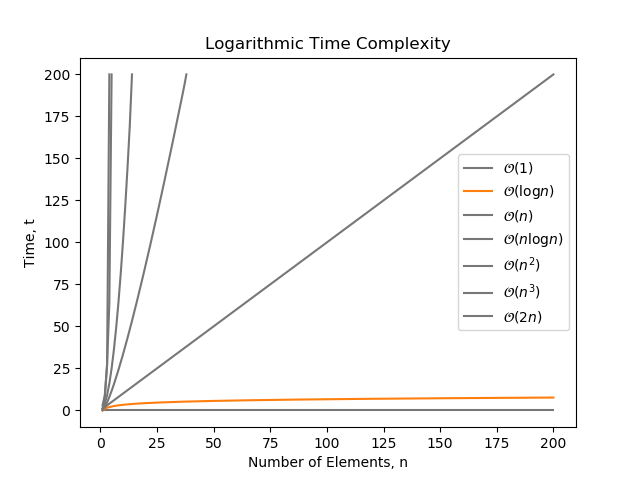
is a time complexity where the number of operations grows with the logarithm of the size of the input. complexity is considered to be pretty good. You can think of it as: Every time the size of the input doubles, the complexity increases by a constant amount.
Note that whenever we are talking about software algorithms with complexity, we are usually referring complexity (due to the binary nature of most algorithms). However, this does not matter, as all logarithmic complexities belong to the same class, no matter what the base is. The base is just a constant factor which again disappears (e.g. , no matter what base is used).
i = 0while i < n: print('hello') i *= 2 # Double i each time, making it O(log n)Notice the i *= 2, which makes in run in time.
Common software operations that have complexity are:
- Finding an element in a binary search tree. a 1-node binary tree has height , a 2-node binary tree has height , a 4-node binary tree has height , and so on. An n-node tree has height , so adding elements to the tree causes the height to grow logarithmically with the number of inputs.
- A binary search algorithm. On each iteration you half the number of elements remaining in the search space.
- The best way to calculate Fibonacci numbers (the easiest way with recursion is !).
- Calculating .
- Other “divide-and-conquer” style algorithms.
Linear Time
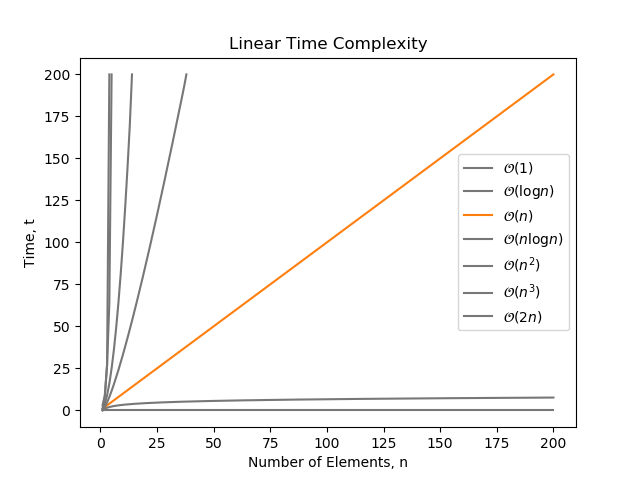
Linear time is when an algorithm grows at a rate proportional to the number of elements, . A simple for loop has complexity:
for i in range(n): print('hello')Another example:
for i in range(0, n, 2): # Increment n by 2 each time print('hello')Note that even though the above example prints “hello” for every second (so it performs prints), it still has complexity (remember that coefficients are dropped).
nlog(n) Time
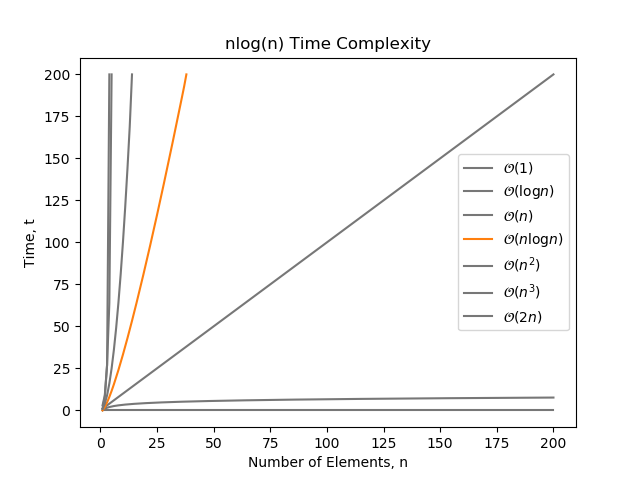
complexity can be thought of as a combination of and complexity (and more often than not, this is how the algorithm actually works). It is famously known as the best complexity that you can sort an arbitrary collection of elements in.
This can be demonstrated by a nested for loop, one having complexity and the other complexity:
for i in range(n): j = 0 while j < n: print('hello') j *= 2 # This inner loop is log(n)Examples of complexity:
- Merge sort
- Heap sort
- Quick sort
n^2 Time
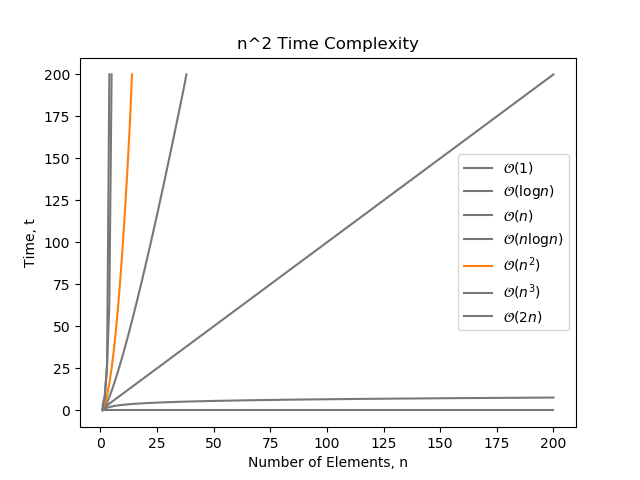
complexity is proportional to the square of the number of elements . This is a bad form of complexity to have, especially when grows large.
The most basic example of is a pair of nested for loops, each iterating over every element:
for i in range(n): for j in range(n): print('hello')Here is another example which has complexity:
for i in range(n): for j in range(n): print('hello')
for i in range(n): for j in range(n): print('hello')Note that this is just a 2x repetition of a algorithm with complexity. Repeating an algorithm (i.e. performing it twice) does not change the complexity.
n^3 Time
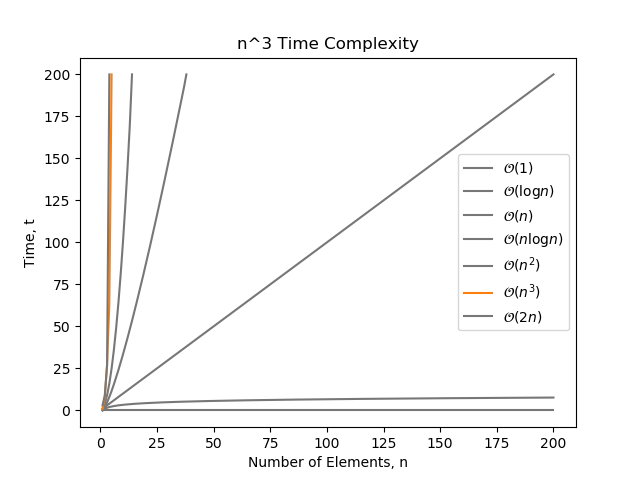
complexity is rarely seen in a single software algorithms (but can easily arise from the combination of multiple algorithms to solve a problem).
for i in range(n): for j in range(n): for k in range(n): print('hello')Naturally, we could keep going forever explaining poorer and poorer complexities (, , e.t.c), but I think by now you understand the concept, and these higher complexities are rarely seen in real software algorithms.
2^n Time
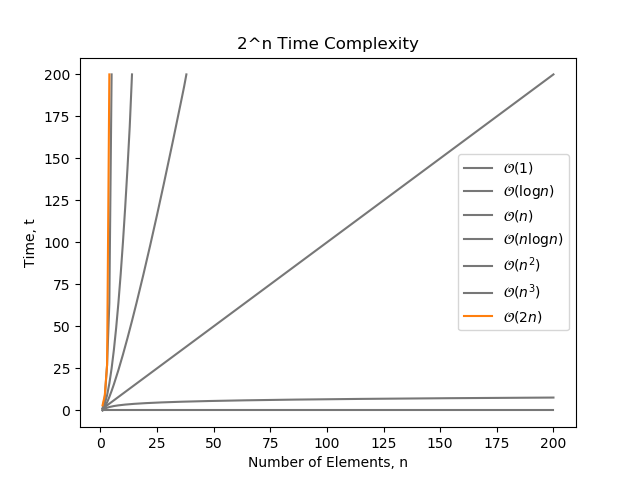
Exponential time is written as . Exponential time is always greater than any polynomial time, e.g. grows faster than .
An example of time is the naive (and simple) implementation of an algorithm that calculates the Fibonacci sequence, without the use of dynamic programming. It would look something like this:
def fibonacci(n): if n <= 1: return n else return fibonacci(n - 1) + fibonacci(n - 2)n! Time
Factorial time is written as . It is a very rare and hugely expensive complexity class. Permutation algorithms.
Exotic Times
- The infamous Bogo sort runs in time.
Amortized Complexity
When we talk about amortized complexity, we are referring to complexity per run, as the number of runs goes to infinity. This means that if sometimes, the runtime is much longer, as long as this event is infrequent enough, the amortized complexity can still be quite good.
In formal terms:
Amortized complexity is the total expense per operation, evaluated over a sequence of operations.
For example, take the example of adding a value to an array. The array starts of being able to hold one value, and it’s size is doubled every time we run out of space. When we add a value, it normally doesn’t need resizing, which is . But when adding the 1st, 2nd, 4th, 8th, 16th, e.t.c value, we need to resize the array. This takes . The probability of having to resize the array is . This gives an amortized complexity of .
Amortized complexity is not the same thing as average complexity.