November 2022 Updates
Added real world EMC measurements to the Electromagnetic Compatibility (EMC) page.
Added a new page on the HU3PAK Component Package.
Added the new page Running Rust on Microcontrollers.
Changed the code block theme from
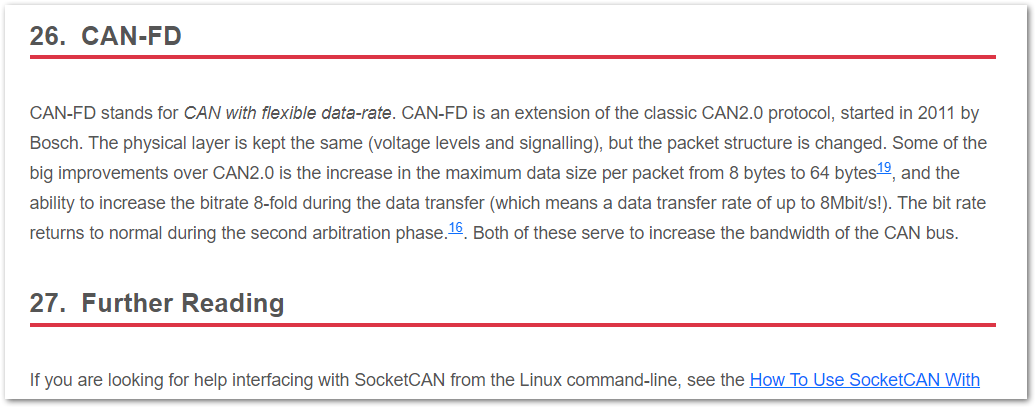
rainbow_dash(light theme) tomonokai(dark theme) as I feel as it’s easier to read.Added info on the CAN-FD (CAN with flexible data-rate) standard.
Converted the Capacitors page from Asciidoc to Markdown format, and added new image with various capacitor schematic symbols (incl. the Japanese-style symbol).




October 2022 Updates
Updates This Month
Added information on MQTT message ordering.
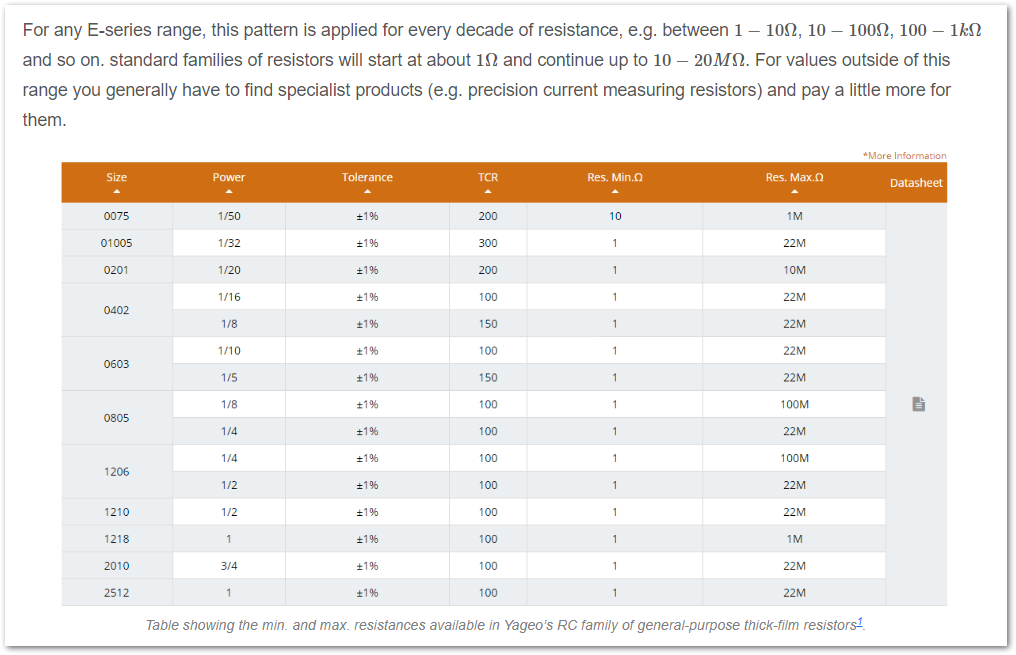
Added standard max. and min. resistances for E series resistors.
Added info on BJT leakage currents.
Added a
fileshortcode to load content from relative files into the main Markdown file. This is used to load a Python generated HTML table (which is saved to a separate file) into the primary Markdown file.Added info on circuit breaker ICs.
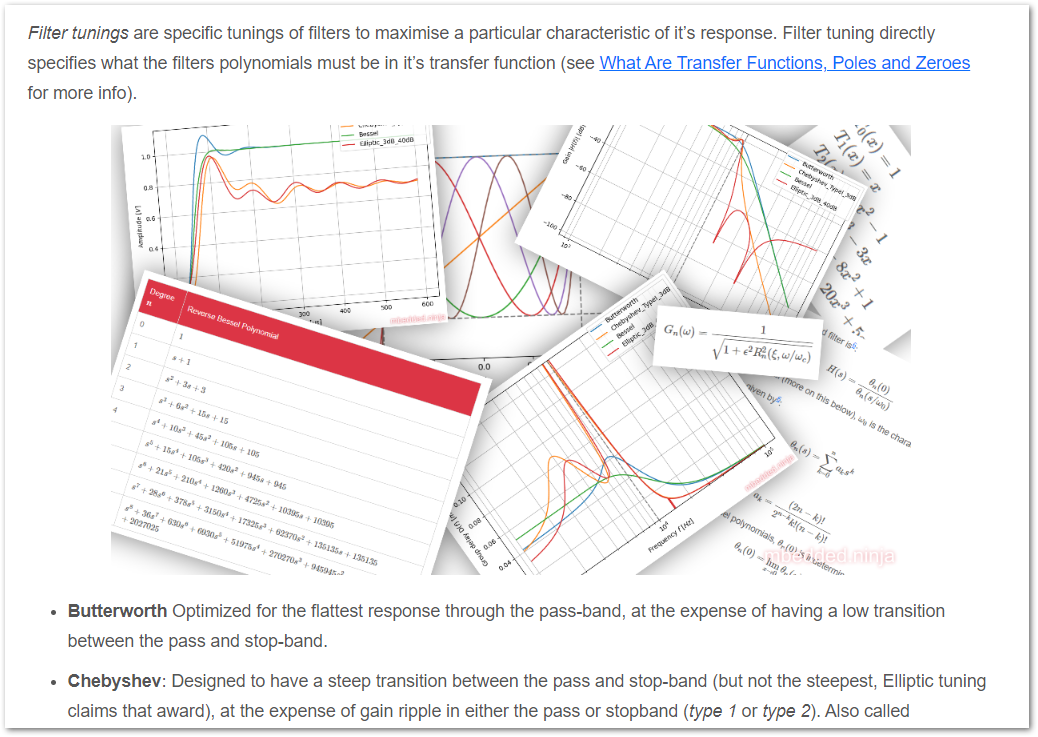
Added more info on filter tunings including Chebyshev equations and plots, Bessel filter tunings, using the sympy Python package to generate tables of factored Butterworth filter polynomials, equations to find the normalized Butterworth tuning (filters) polynomials, bode plots of various order Butterworth tunings.
Added more info to the What Are Transfer Functions, Poles, And Zeroes? page, including Laplace transformations, info on Wolfram Alpha’s ability to analyze transfer functions.
Added info on the popular S8050 NPN BJT to the Bipolar Junction Transistors (BJT) page.
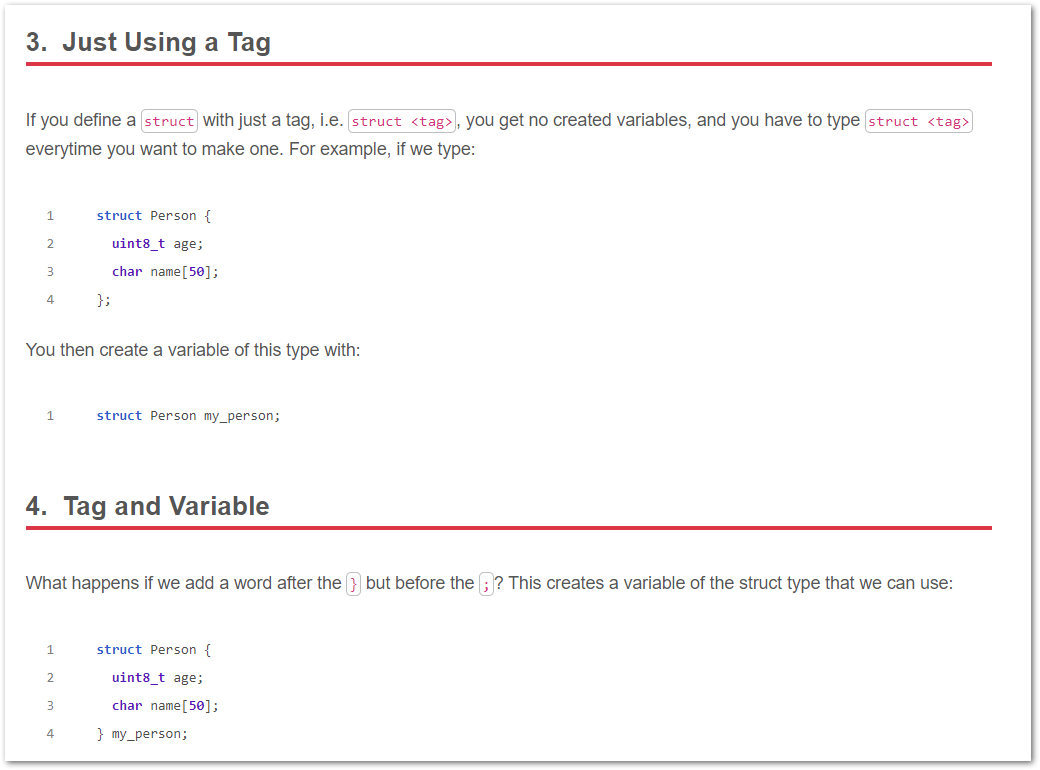
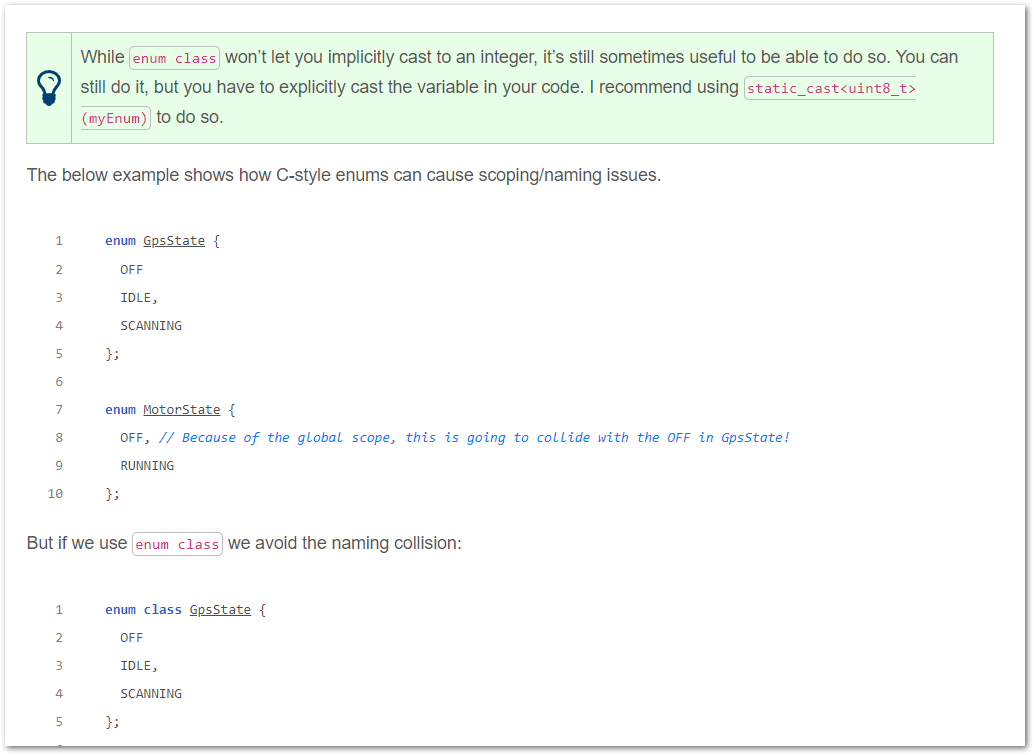
Added a new page on the differences between using struct and typedef struct in the C programming language.




September 2022 Updates
Updates This Month
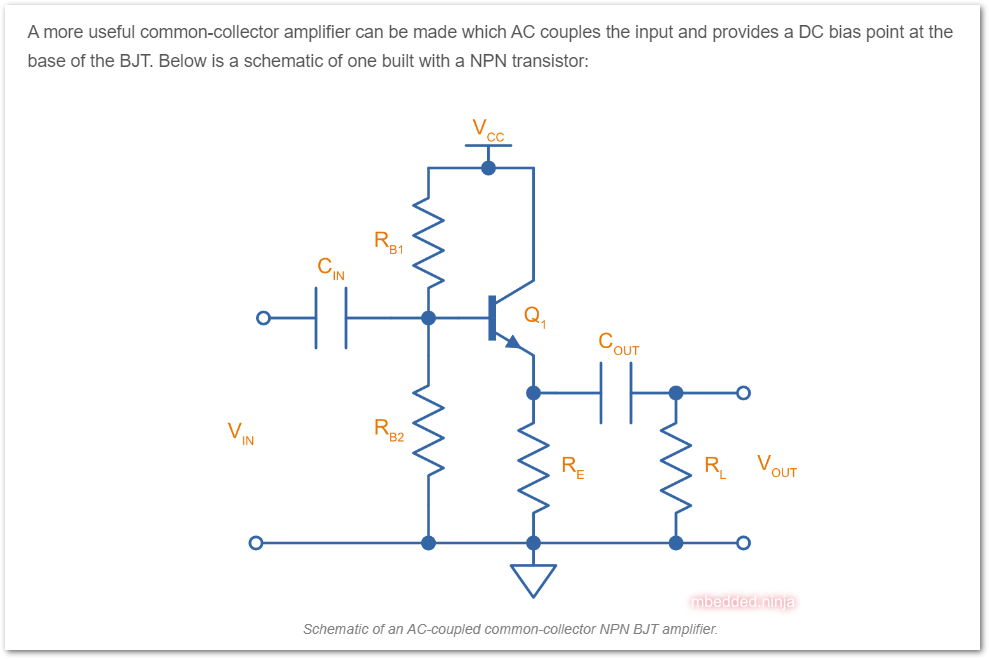
Create a new page for the BJT common-collector amplifier.
Updates to the Kalman Filter page.
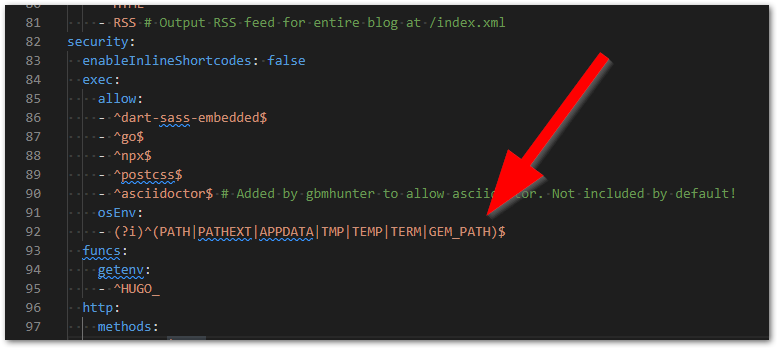
Upgraded the Netlify build image from Ubuntu Xenial 16.04 (which is deprecated and was going to be unsupported in November 2022) to Ubuntu Focal 20.04. This initially caused a hugo build failure, which was resolved by adding
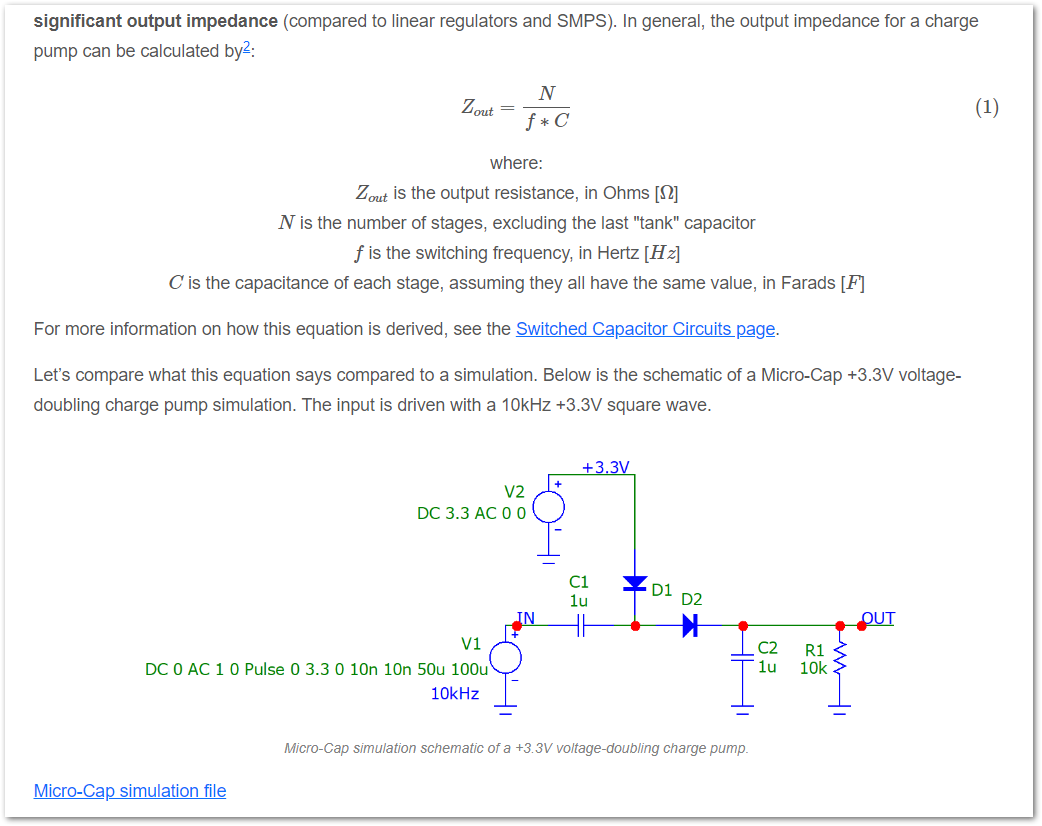
GEM_PATHto thesecurity: exec: osEnv:section of theconfig.yaml.Added info on charge pump output impedance.
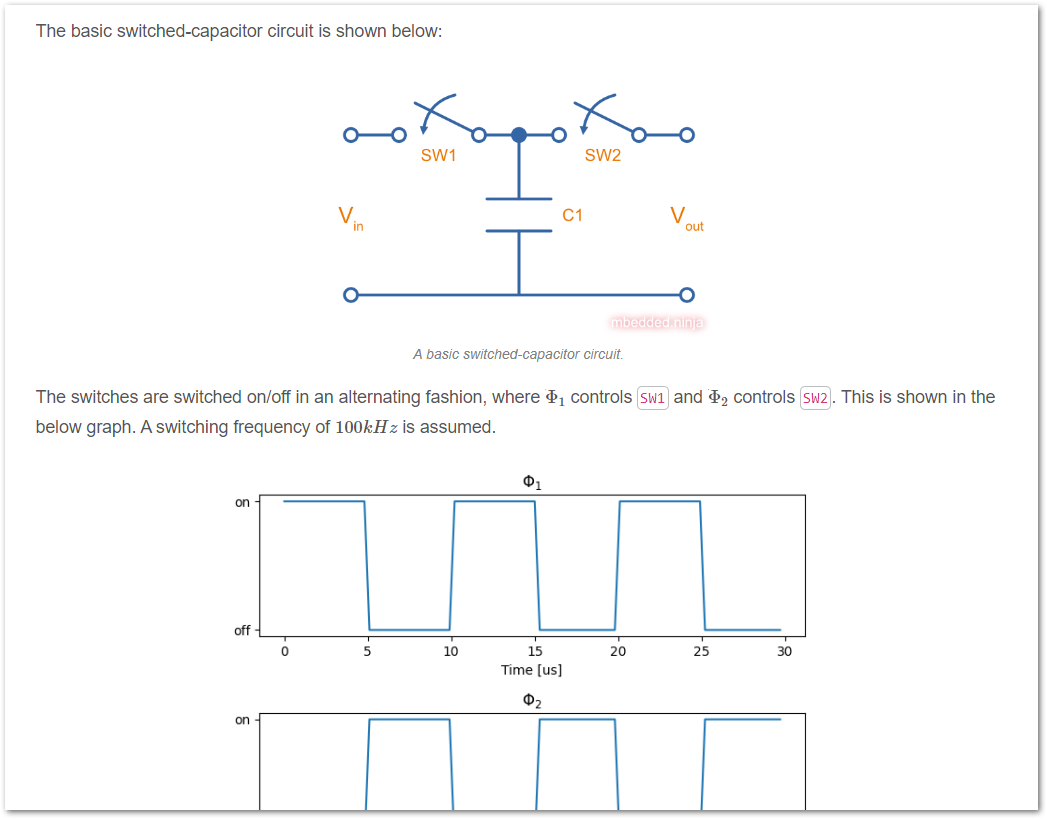
Added a new page on switched-capacitor circuits.
Converted the Analogue Filters page from Asciidoc to Markdown.
Added info on Elliptic filters.
Moved the info on Sallen-Key filters into it’s own page. Added more info on low-pass and high-pass Sallen-Key filters, along with simulated examples and info on their high-frequency limitations.
Moved the PCB Design->PCB Manufacturing And Assembly Considerations page to Electronics->Circuit Design->The Schematic And PCB Design Guide.
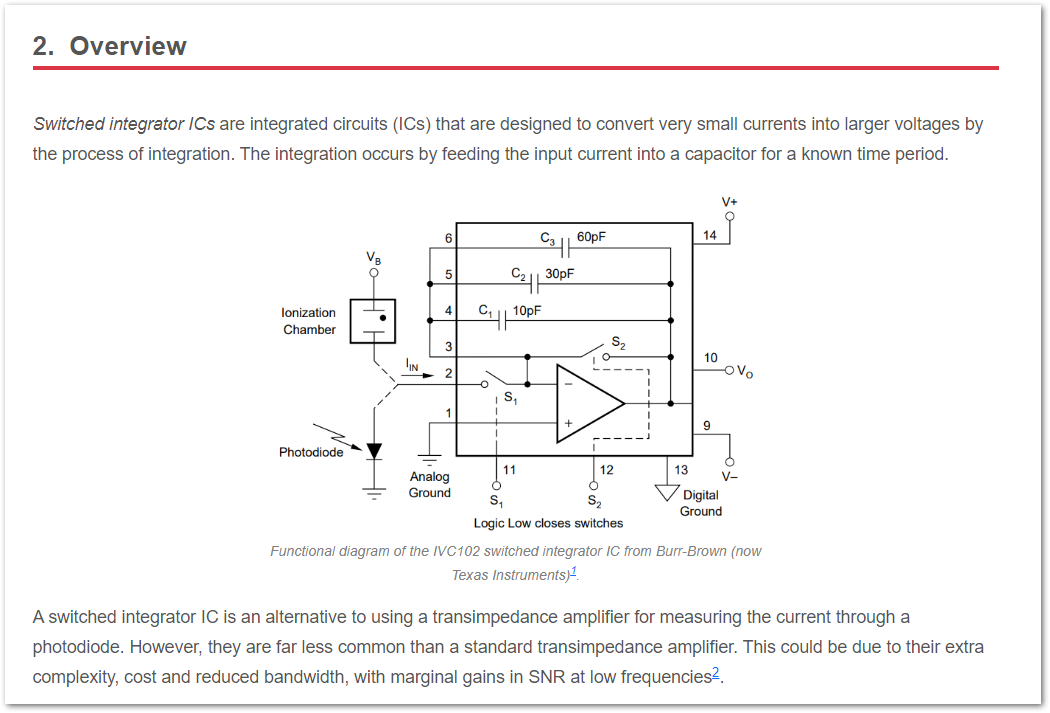
Added a new page on Switched Integrator ICs.
Updated the C++ On Embedded Systems page with more info and examples on what C++ features you should and shouldn’t use in an embedded system. Also replaced a code example that was using a pointer to use a reference.

August 2022 Updates
Updates This Month
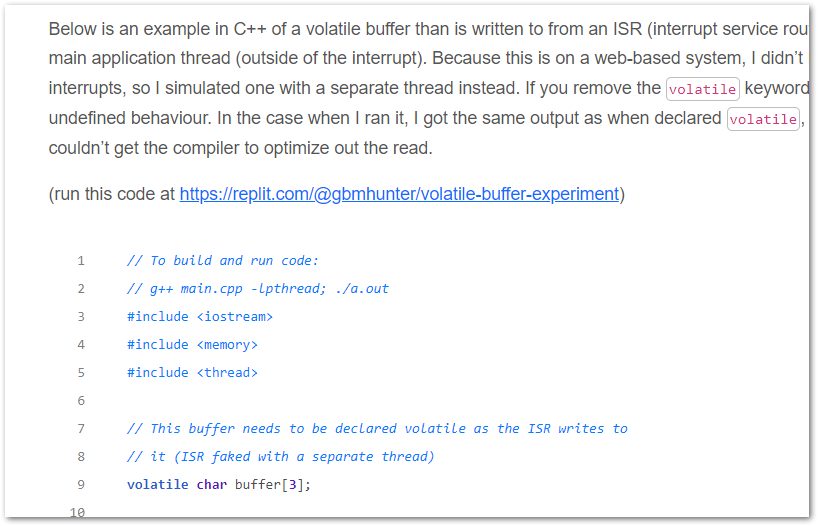
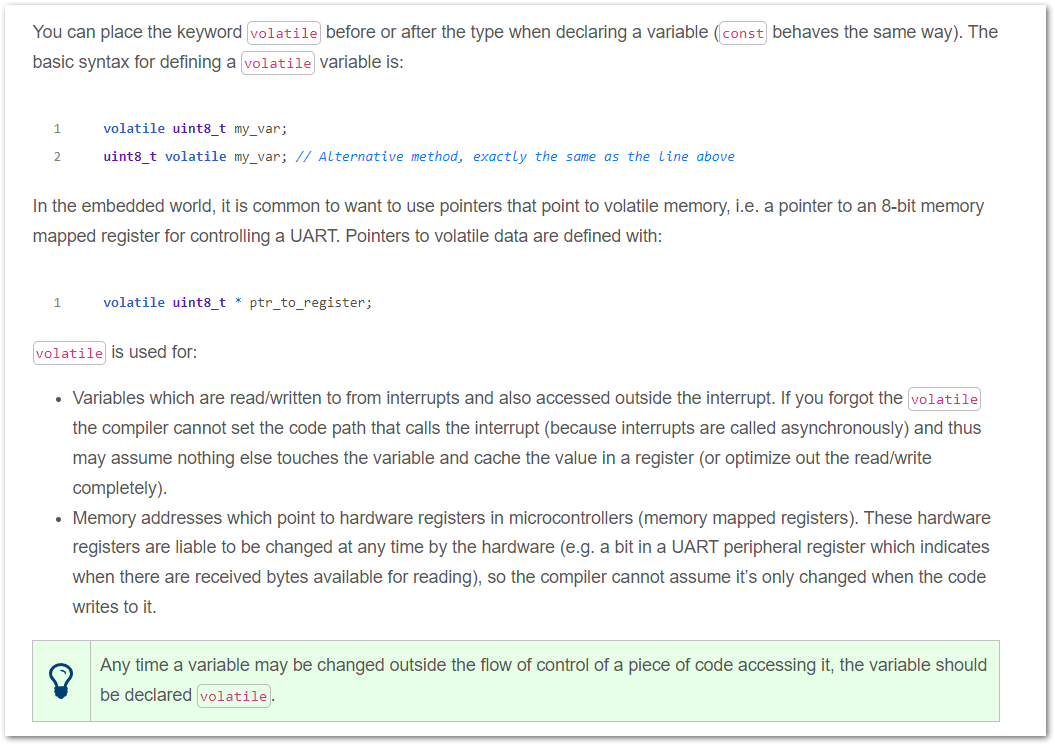
Added a page with info on using the volatile keyword in firmware.
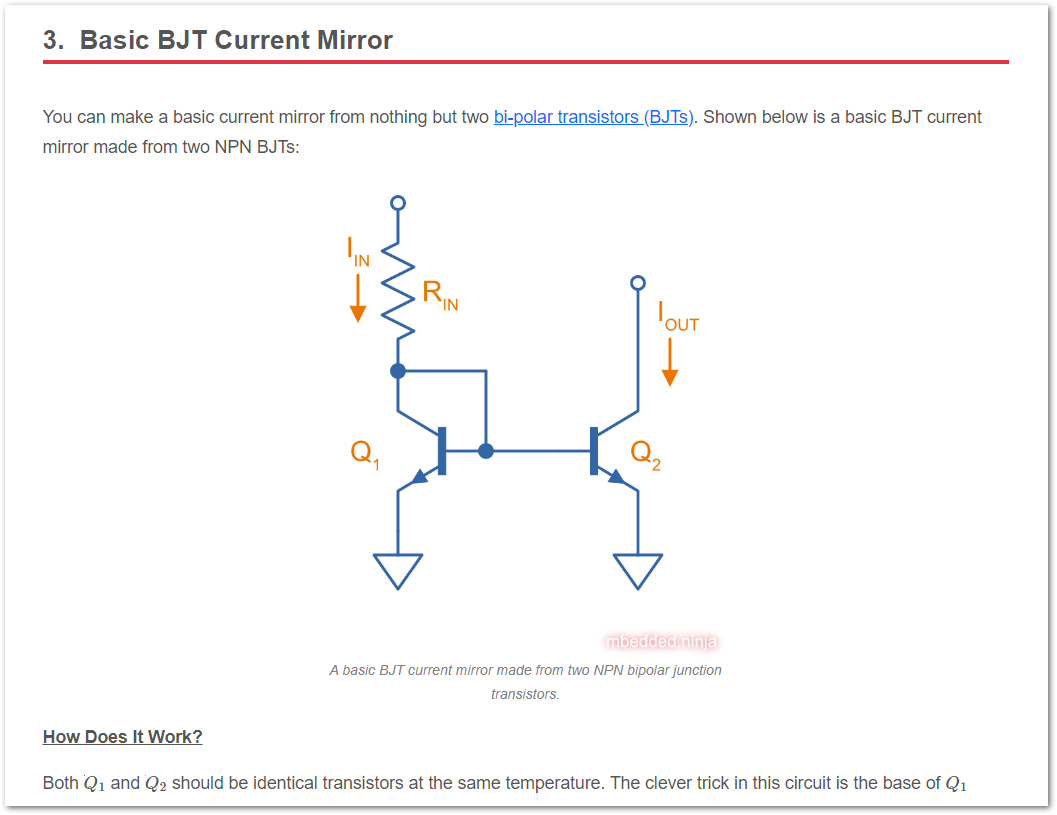
Added a page on current mirrors.
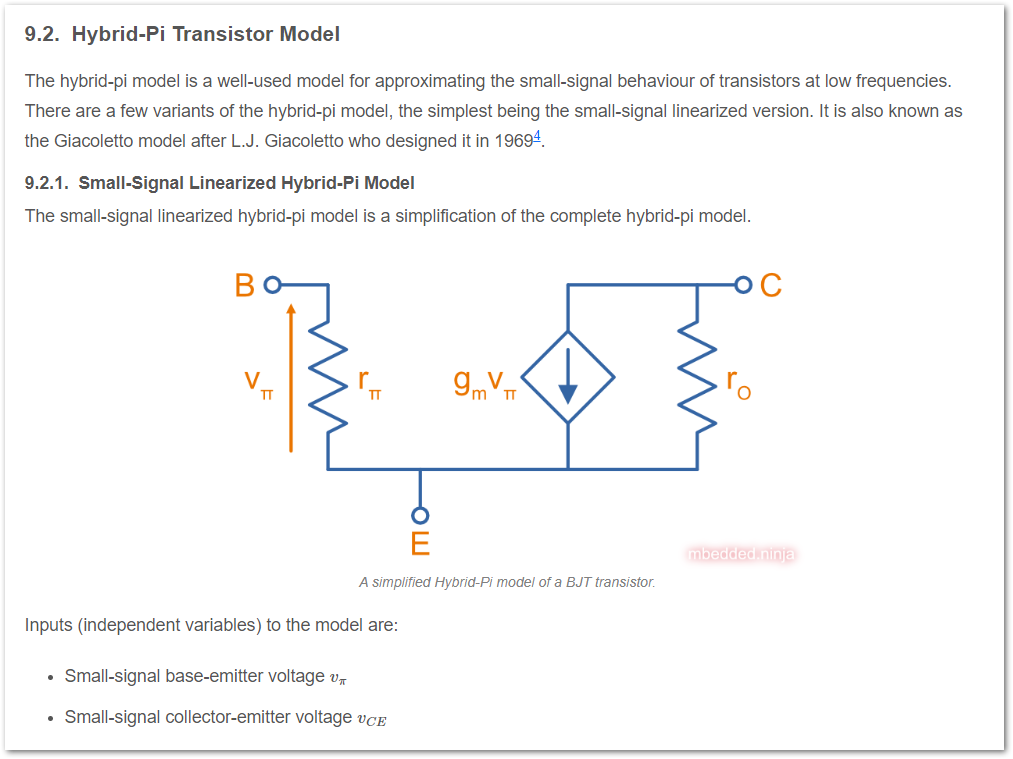
Added more info on the Hybrid-pi BJT model.
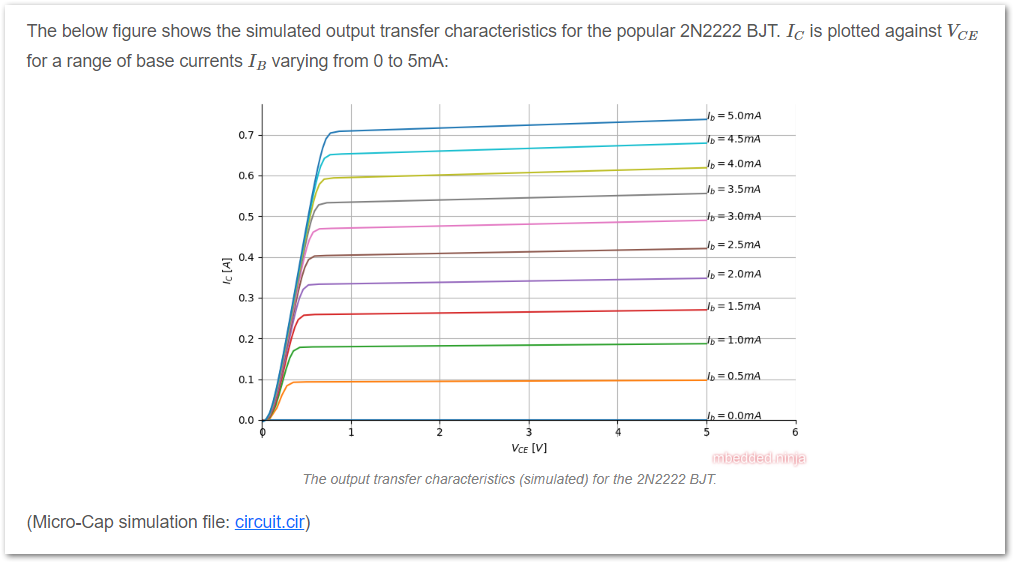
Added info on BJT output transfer characteristics.
Added a new page with info on the common emitter BJT amplifier.
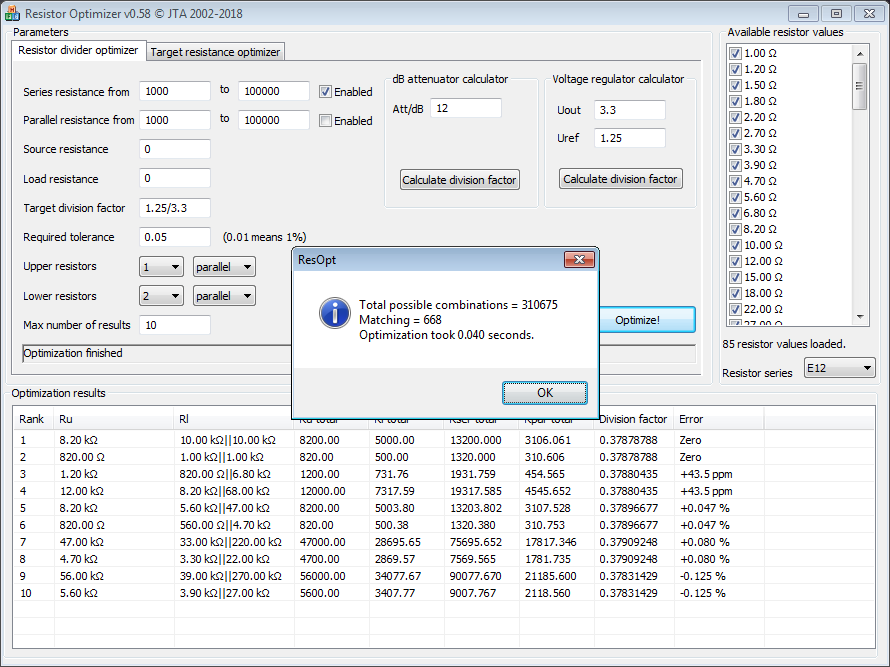
Added info on the Resistor Optimizer tool.
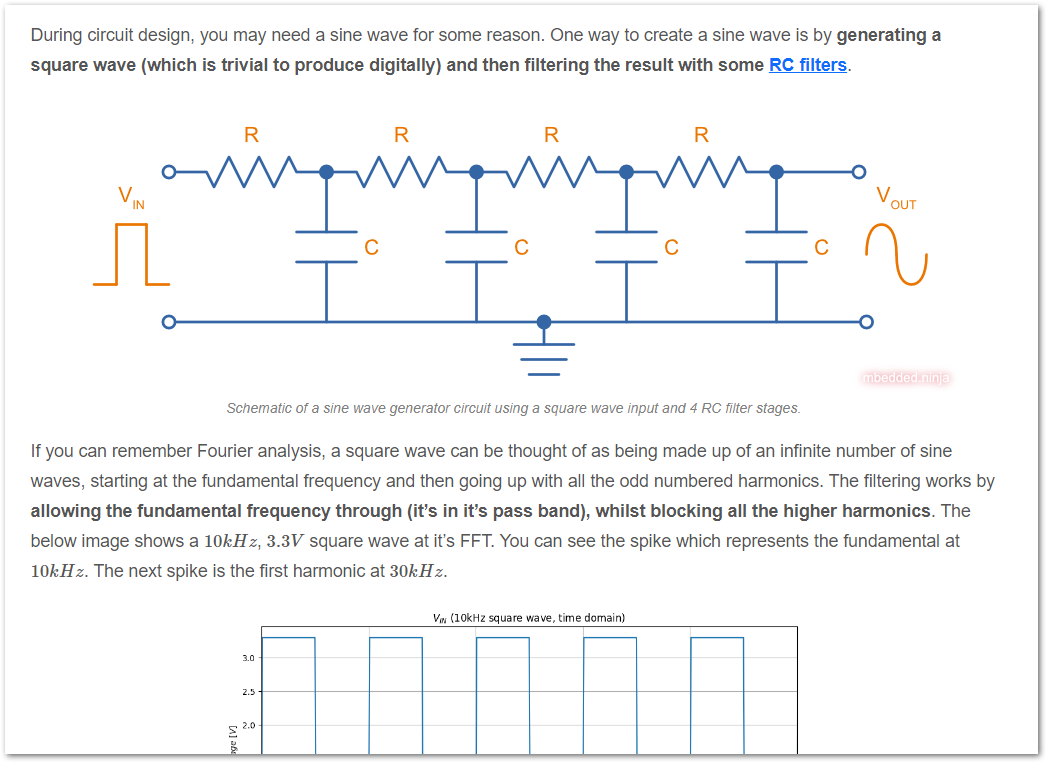
Added the new page How To Create Sine Waves From Square Waves And RC Filters.
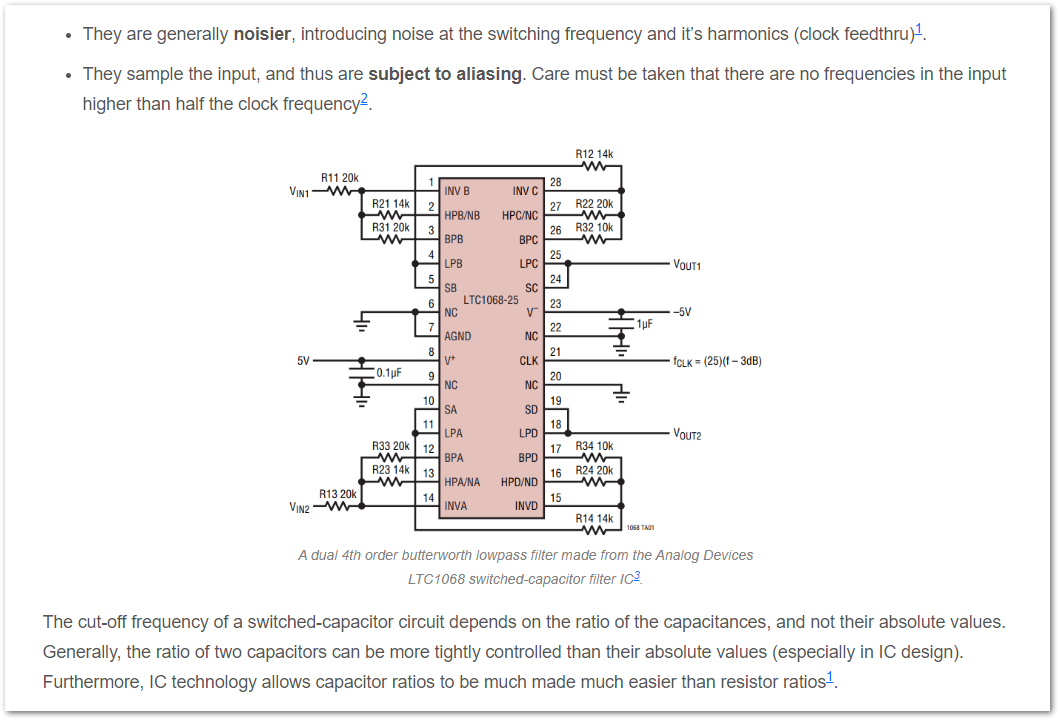
Added a new page on Switched Capacitor Filters.

July 2022 Updates
Updates This Month
Changed the left side-bar, main content and right side-bar columns widths at various screen breakpoints to make the main content larger on wider screens.
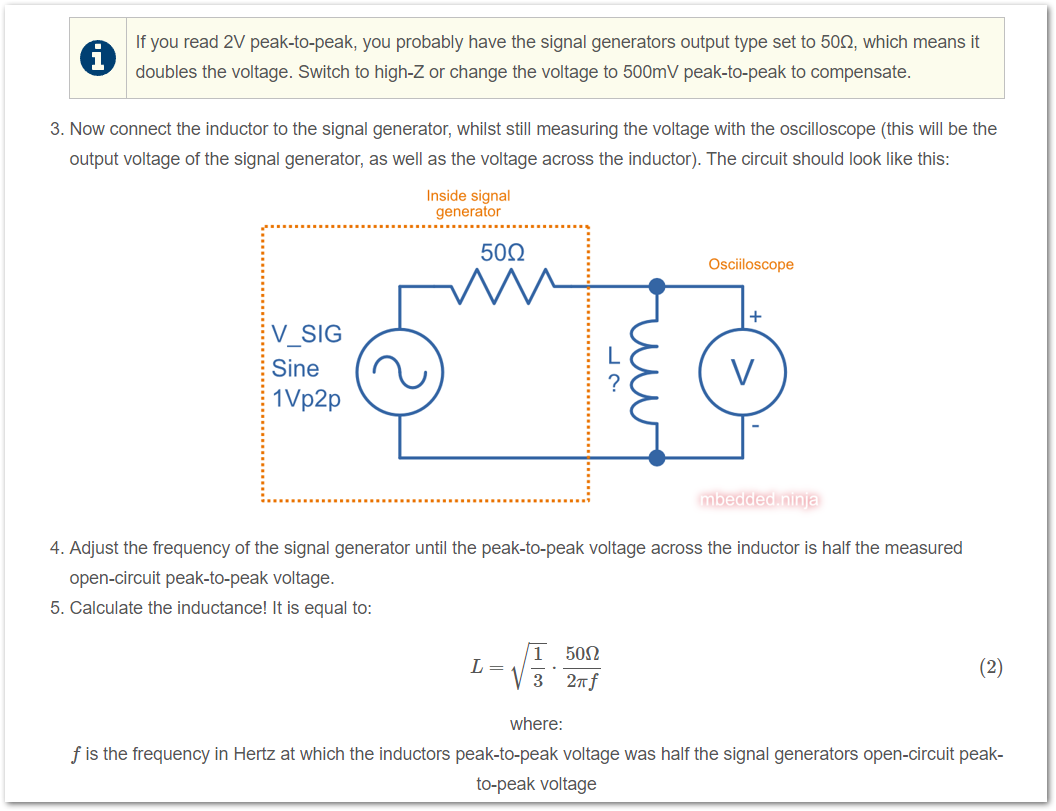
Added a how-to on an easy method for measuring inductance using a signal generator and oscilloscope.
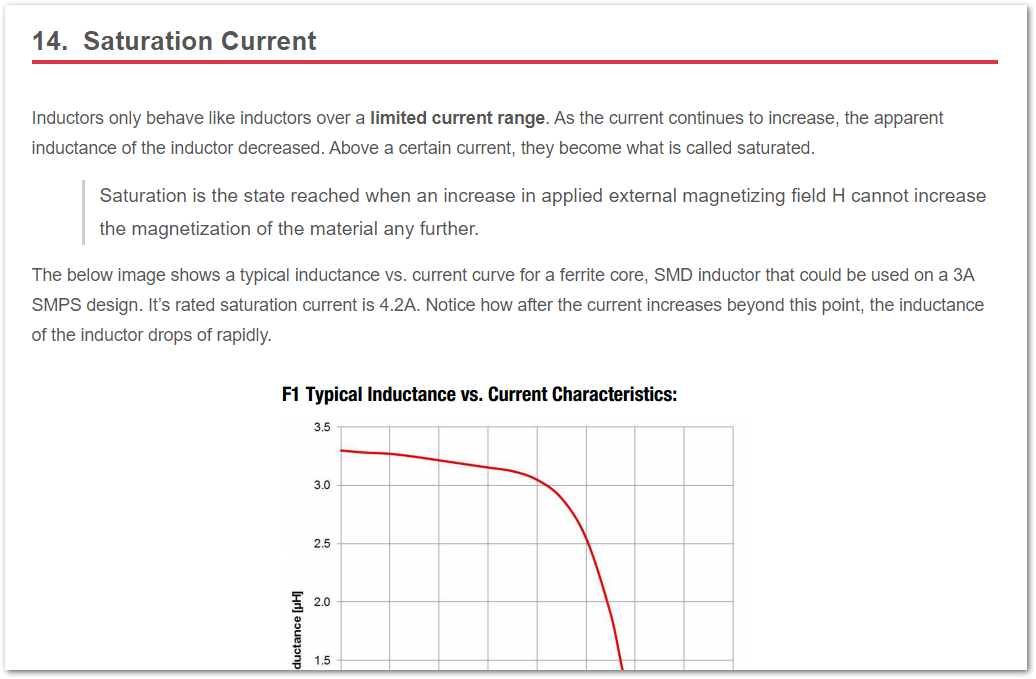
Updated info on the saturated current of an inductor.
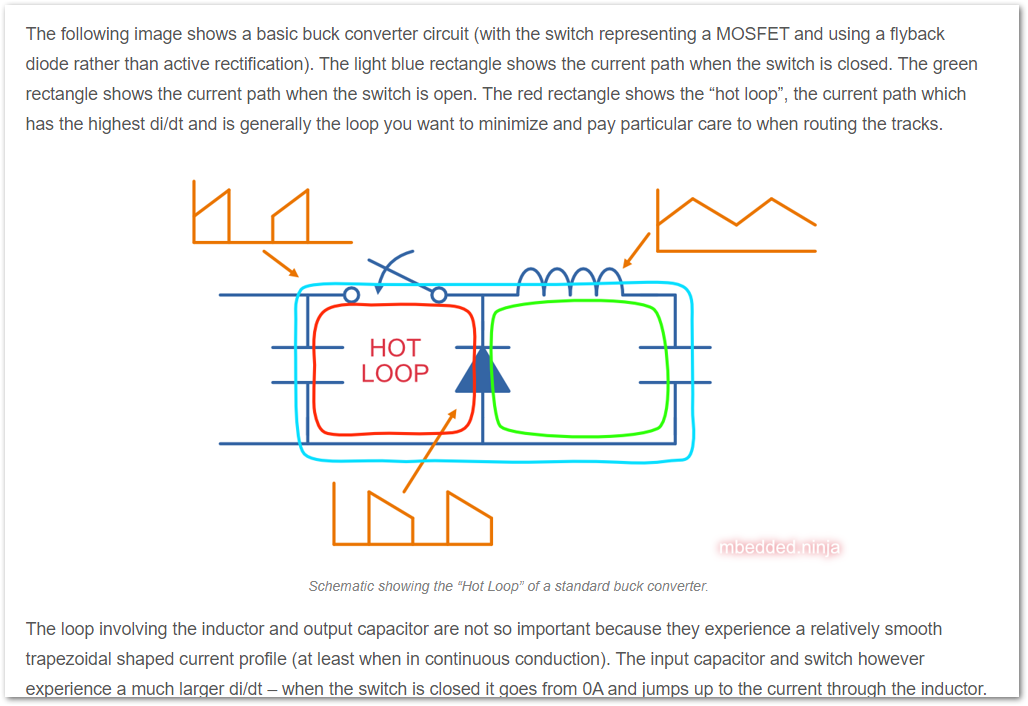
Started a page on
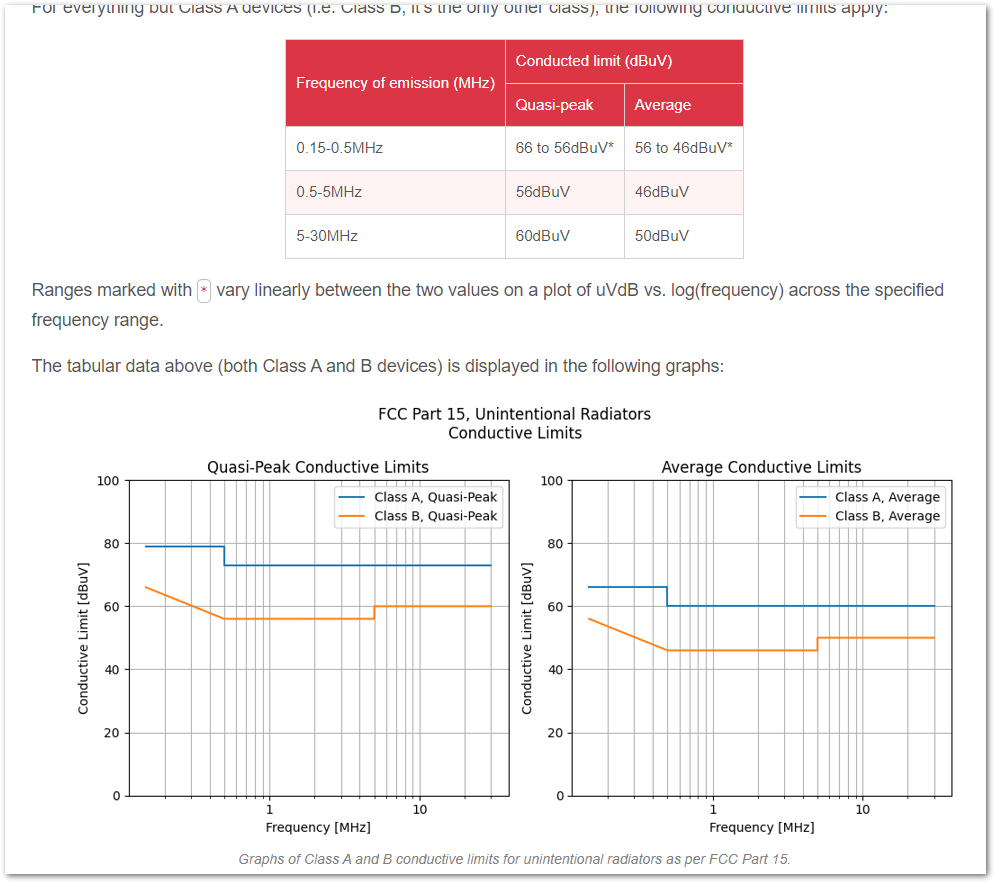
SMPS EMC and hot loops.Added FCC Part 15 conductive limits and CISPR 11 info to the EMC page.
Tied up the SMPS pages.
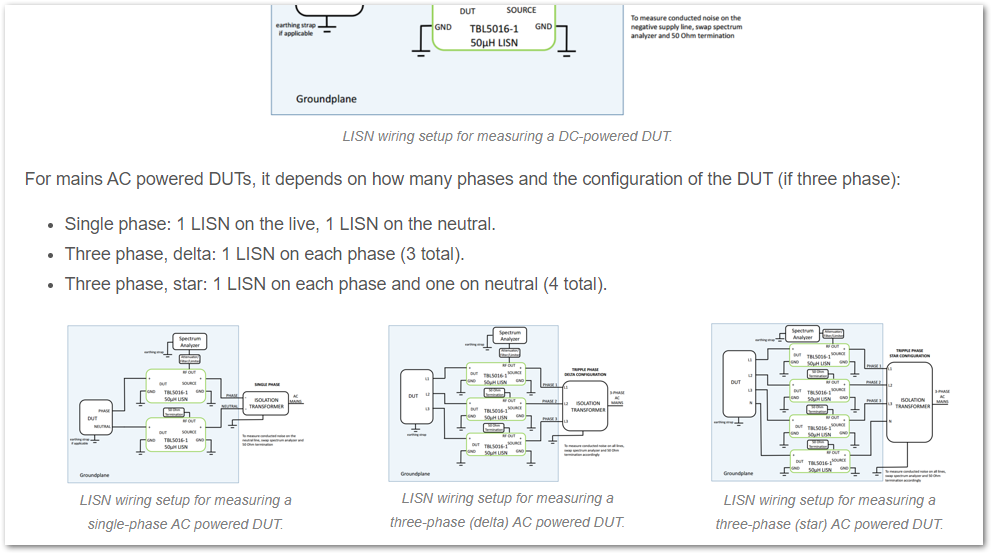
Added info on LISNs.
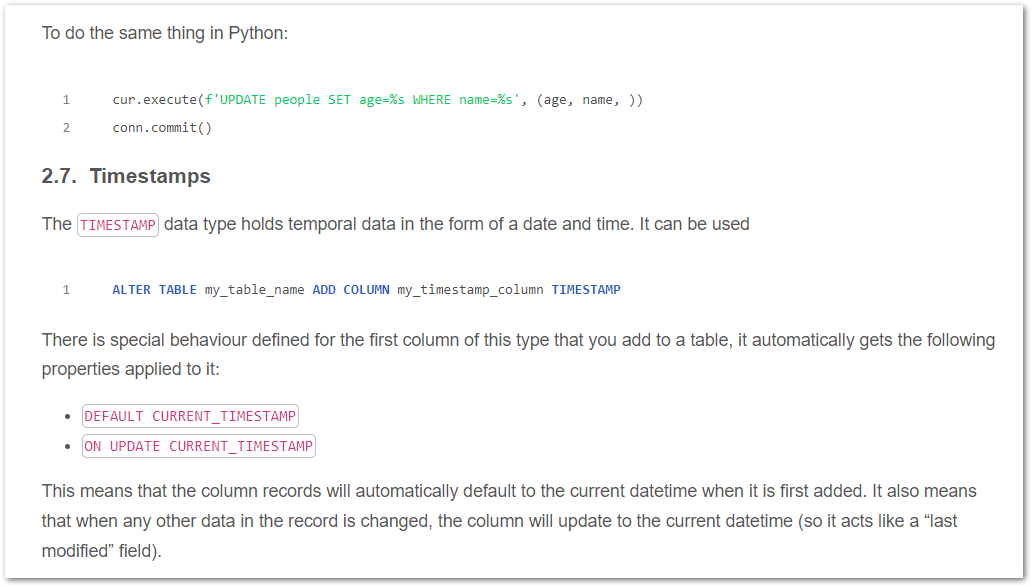
Added more info on SQL, MySQL and MariaDB.
Added a new page on thermal jumper chips.
Added the new page Embedded Systems And The Volatile Keyword.

{kind=link}
{kind=link}